Is there a human pose estimation model compatible with this board?
Or, could I know about models that are not compatible?
Please reply @Louis-Cheng-Liu
Hello @afa1414 ,
Sorry, we do not have demo about human body pose.
About how to know the model can infer on board. Actually, have not a comprehensive way to judge. This depends on whether the model has unsupported structure.
I can share our experience. Try to keep only the general structure(convolution, linear and pooling) in the model and get rid of postprocess structure. Each model has its own postprocessing method. It is so much that we could not support all of them. For this situation, we will remove postprocess structure in model. When you infer convert on board, as you remove them, you need to do preprocess and postprocess in codes. Both our YOLOv7 and YOLOv8 model are this way.
How to determine which structure in the model is the preprocess structure or the postprocess structure?
A easy way, from input to first convolutional layer is preprocess and from output to the last layer(convolution, linear, pooling or activation) is postprocess. Use your model as example.
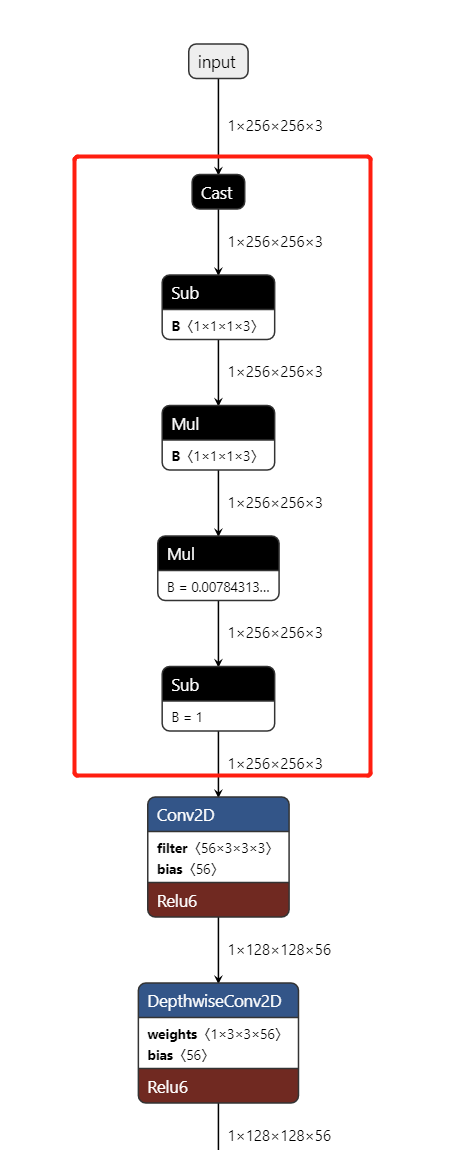
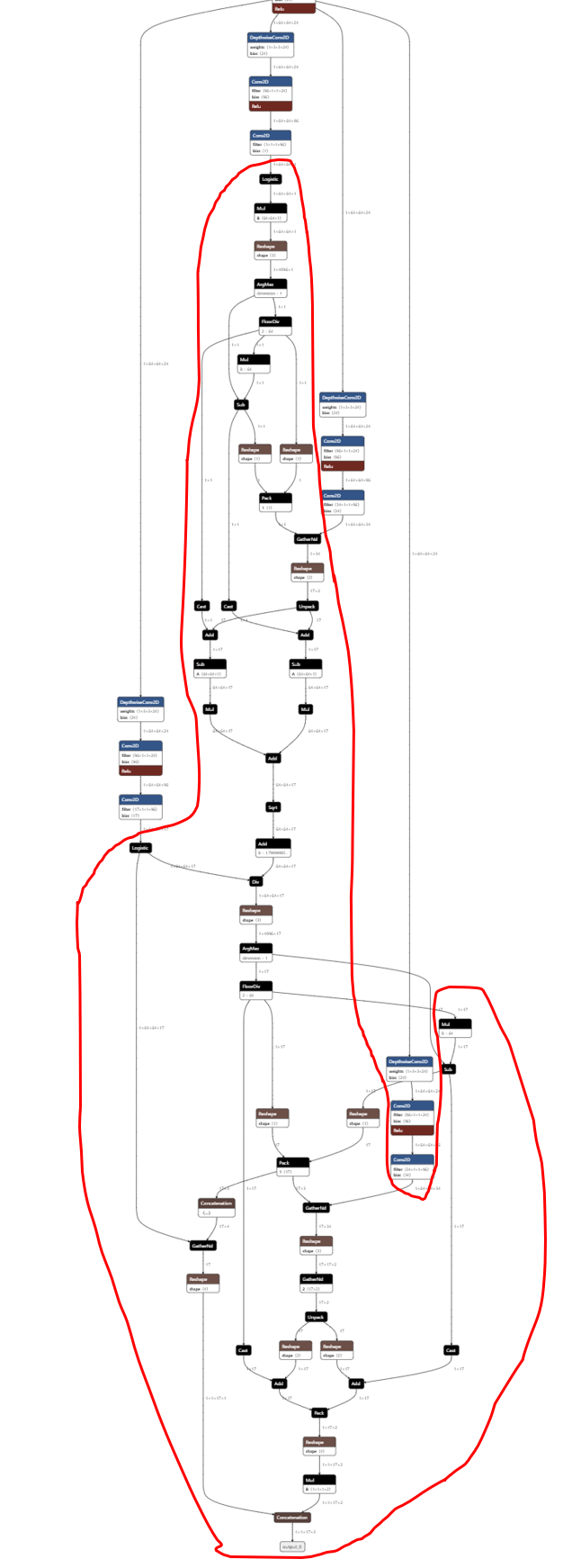
Hope it is helpful to you.
If I remove the preprocessing and postprocessing steps from the model and perform these steps within the KSNN code, would it increase the possibility of using multiple models?
Hello @afa1414 ,
If this model can do what you want to do, after removing and adding preprocess and postprocess Python codes, it also can do it.
For example, if model output is y and postprocess is add 1.
If not remove, npu.nn_inference will return y+1. If remove, it will return y and then you need to add this code after npu.nn_inference.
y = npu.nn_inference()
y = y + 1
Thank you for your response. It was very helpful.
I’m trying to first convert the YOLOv8n pose model to ONNX and then convert it using the aml_npu_sdk. However, I’m not sure if the process of removing and adding the preprocessing and postprocessing steps is covered on this site.
I followed the instructions on the site to modify the head file and convert the model to ONNX, and then used the following process to convert it:
./convert --model-name yolov8n_pose_onnx \
--platform onnx \
--model /home/ss/model/yolov8/yolov8n-pose.onnx \
--mean-values '0 0 0 0.00392156' \
--quantized-dtype asymmetric_affine \
--source-files /home/ss/aml_npu_sdk/acuity-toolkit/python/dataset.txt \
--batch-size 1 \
--iterations 1 \
--kboard VIM3 --print-level 0
I then wrote the following code:
import numpy as np
import os
import argparse
import sys
import cv2 as cv
import time
from ksnn.api import KSNN
from ksnn.types import output_format
mean = [0, 0, 0]
var = [255]
def preprocess_image(image, mean, var):
img = cv.resize(image, (640, 640)).astype(np.float32)
img[:, :, 0] = img[:, :, 0] - mean[0]
img[:, :, 1] = img[:, :, 1] - mean[1]
img[:, :, 2] = img[:, :, 2] - mean[2]
img = img / var[0]
img = img.transpose(2, 0, 1)
return img
def draw_skeleton(image, keypoints, threshold=0.2):
for i in range(0, len(keypoints), 3):
x = int(keypoints[i] * image.shape[1])
y = int(keypoints[i + 1] * image.shape[0])
conf = keypoints[i + 2]
if conf > threshold:
cv.circle(image, (x, y), 5, (0, 255, 0), -1)
return image
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--library", help="Path to C static library file")
parser.add_argument("--model", help="Path to nbg file")
parser.add_argument("--device", help="the number for video device")
parser.add_argument("--level", help="Information printer level: 0/1/2")
args = parser.parse_args()
if not args.model or not os.path.exists(args.model):
sys.exit("NBG file not found !!! Please use format: --model")
if not args.device:
sys.exit("Video device not found !!! Please use format :--device ")
if not args.library or not os.path.exists(args.library):
sys.exit("C static library not found !!! Please use format: --library")
level = int(args.level) if args.level in ['1', '2'] else 0
yolov8_pose = KSNN('VIM3')
print(' |---+ KSNN Version: {} +---| '.format(yolov8_pose.get_nn_version()))
print('Start init neural network ...')
yolov8_pose.nn_init(library=args.library, model=args.model, level=level)
print('Done.')
cap = cv.VideoCapture(int(args.device))
cap.set(3, 1920)
cap.set(4, 1080)
while True:
ret, orig_img = cap.read()
if not ret:
break
img = preprocess_image(orig_img, mean, var)
cv_img = [img]
start = time.time()
outputs = yolov8_pose.nn_inference(cv_img, platform='ONNX', reorder='2 1 0', output_tensor=1, output_format=output_format.OUT_FORMAT_FLOAT32)
end = time.time()
print('Inference time: ', end - start)
keypoints = outputs[0].reshape(-1) # Assuming the keypoints are in the first output tensor
orig_img = draw_skeleton(orig_img, keypoints)
# Resize the output window to half the original size
resized_img = cv.resize(orig_img, (orig_img.shape[1] // 2, orig_img.shape[0] // 2))
cv.imshow("Skeleton Detection", resized_img)
if cv.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv.destroyAllWindows()
When I run this code, it seems that a small dot appears in the upper-left corner of the webcam window. Could you help me figure out what the issue might be?
@Louis-Cheng-Liu
Hello @afa1414 ,
From your code i can not make sure what is wrong.
Use this tool open your ONNX model. Netron
Provide a picture about your model outputs like this.
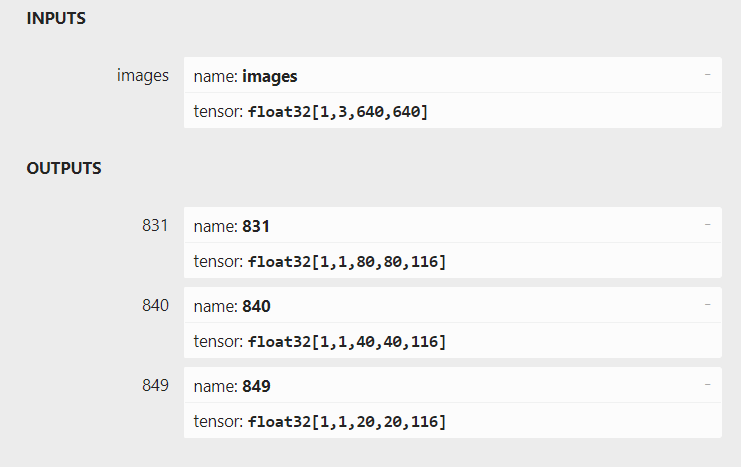

Here it is.@Louis-Cheng-Liu
Hello @afa1414 ,
Your model still has partial postprocess.
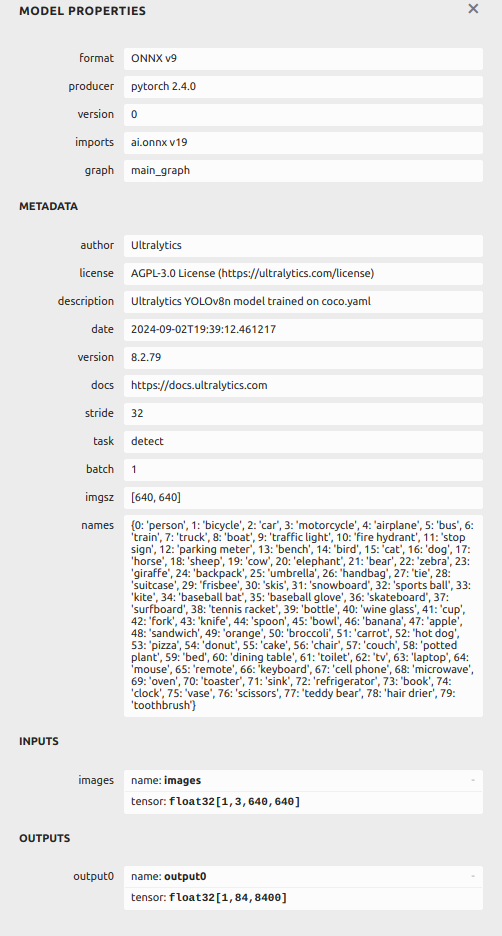
YOLOv8 has three different sizes outputs. 20×20, 40×40 and 80×80. 20×20+40×40+80×80=8400. Original channel number is 116=64+1+17×3.
64 is boxes information. Postprocess will do them to four sides of box (64→4).
1 is boxes confidence. Postprocess will normalize it between 0 to 1.
17×3 is body points. Postprocess will map it to the position of the input image.
Your model, 56 is 4+1+17×3. So i guess your keypoints position is error.
def draw_skeleton(image, keypoints, threshold=0.2):
for i in range(0, len(keypoints), 3): # Not real keypoints position
x = int(keypoints[i] * image.shape[1])
y = int(keypoints[i + 1] * image.shape[0])
conf = keypoints[i + 2]
if conf > threshold:
cv.circle(image, (x, y), 5, (0, 255, 0), -1)
return image
Because of partial postprocess, i am not sure the converted model can infer the right result. You can try it.
Could you provide detailed instructions on how you removed the preprocessing and postprocessing steps from the YOLOv8n model that you worked on
@Louis-Cheng-Liu
Hello @afa1414 ,
The codes i can not find (long time ago). But i can tell you where you should modify.
For YOLOv8 official code GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
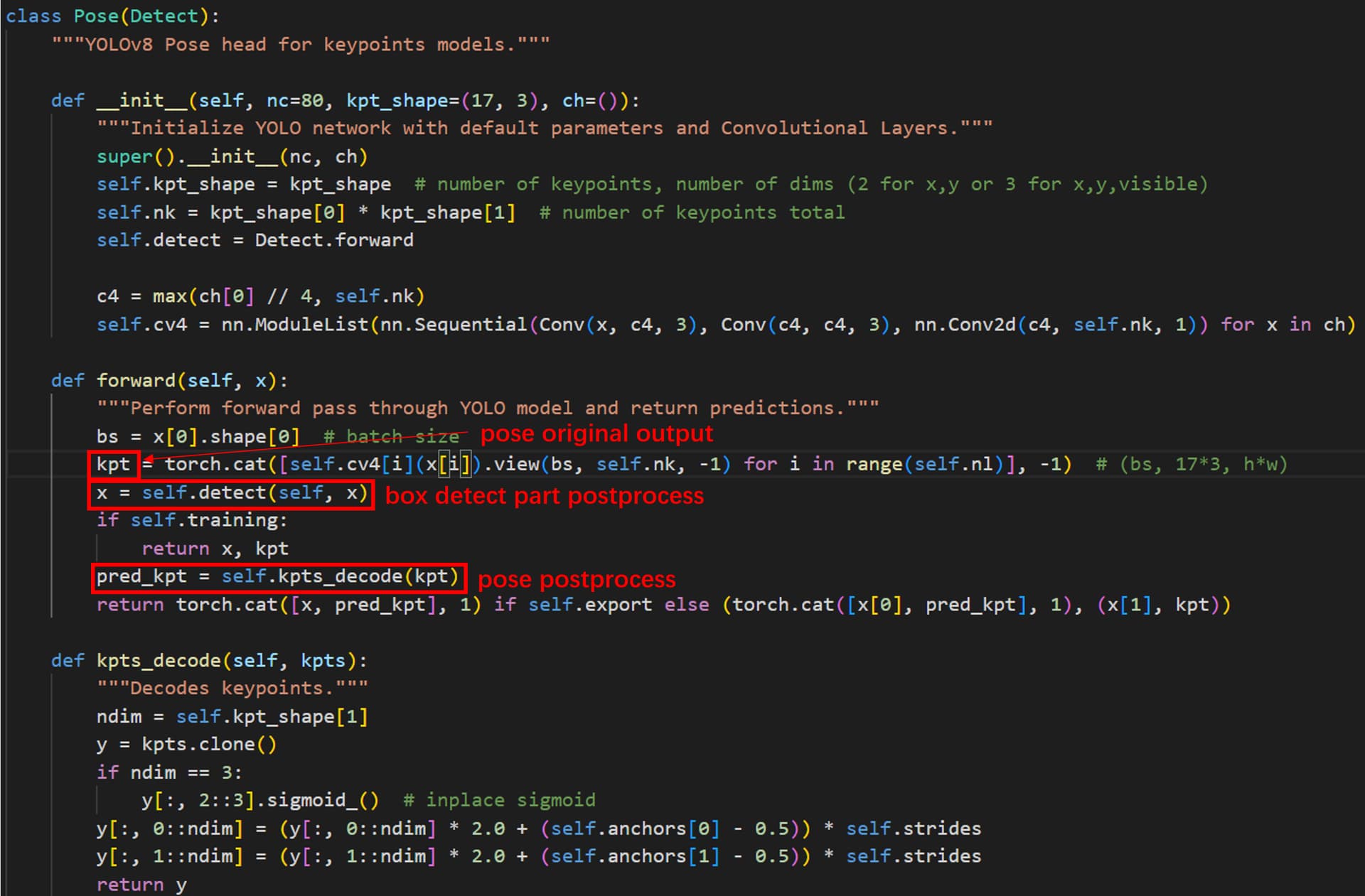
After modifying, run export.py to convert pt model to ONNX.
I found this site: KSNN: OpenPose demo. I found an old file and tried to run it, but the skeleton is not displayed on the webcam output. Is this a demo file that is no longer supported?
@Louis-Cheng-Liu
Hello @afa1414 ,
This demo we do not maintain.
@Louis-Cheng-Liu
I followed the instructions on this site to modify the head file, but the output of the YOLOv8n model converted to ONNX is not coming out as shown in the picture; instead, it looks like this. What should I do?
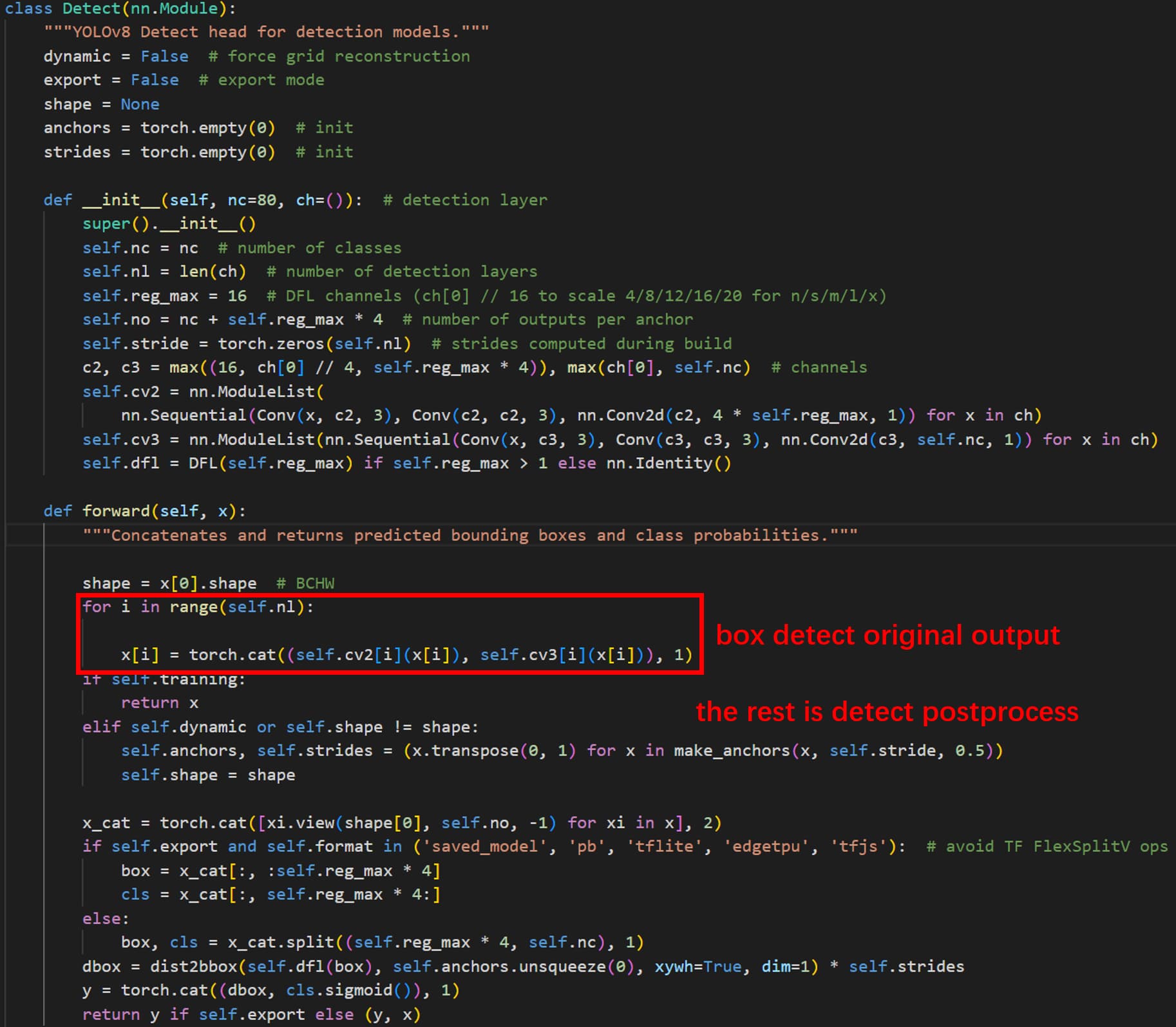
def forward(self, x):
"""Concatenates and returns predicted bounding boxes and class probabilities."""
if torch.onnx.is_in_onnx_export():
return self.forward_export(x)
if self.end2end:
return self.forward_end2end(x)
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # Training path
return x
y = self._inference(x)
return y if self.export else (y, x)
def forward_export(self, x):
results = []
for i in range(self.nl):
dfl = self.cv2[i](x[i]).contiguous()
cls = self.cv3[i](x[i]).contiguous()
results.append(torch.cat([cls, dfl], 1))
return tuple(results)
def forward_end2end(self, x):
"""
These are parts of the head file that I have modified.
This image shows the output results of the model I have converted.
Hello @afa1414 ,
Did you use pip to install ultralytics? If use, you need to modify the file in Python site-package.
Another thing, suggest you use this version of ultralytics and PyTorch. More advanced version may incompatible.
@Louis-Cheng-Liu
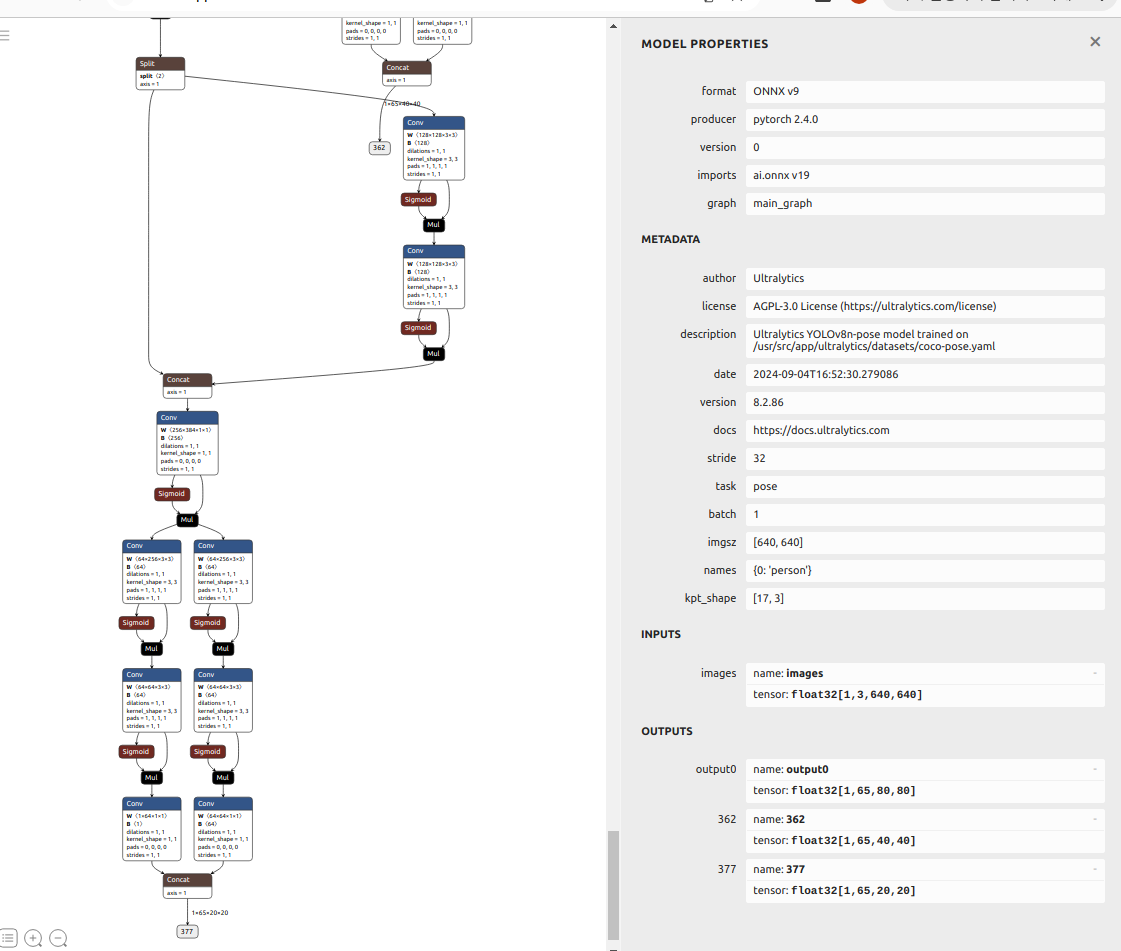
I successfully converted the yolov8n-pose model to ONNX format and wanted the output to appear as follows. I attempted the conversion using the command below, but an error occurred. What should I do?
ss@ss-System-Product-Name:~/aml_npu_sdk/acuity-toolkit/python$ ./convert --model-name yolov8n \
--platform onnx \
--model /home/ss/model/yolov8/yolov8n-pose.onnx \
--mean-values '0 0 0 0.00392156' \
--quantized-dtype asymmetric_affine \
--source-files ./data/dataset/dataset0.txt \
--batch-size 1 \
--iterations 1 \
--kboard VIM3 --print-level 0
--+ KSNN Convert tools v1.4 +--
Start import model ...
2024-09-04 17:28:37.366564: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/ss/aml_npu_sdk/acuity-toolkit/bin/acuitylib:/tmp/_MEIqtPcfB
2024-09-04 17:28:37.366576: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
I Namespace(import='onnx', input_dtype_list=None, input_size_list=None, inputs=None, model='/home/ss/model/yolov8/yolov8n-pose.onnx', output_data='Model.data', output_model='Model.json', outputs=None, size_with_batch=None, which='import')
I Start importing onnx...
WARNING: ONNX Optimizer has been moved to https://github.com/onnx/optimizer.
All further enhancements and fixes to optimizers will be done in this new repo.
The optimizer code in onnx/onnx repo will be removed in 1.9 release.
W Call onnx.optimizer.optimize fail, skip optimize
I Current ONNX Model use ir_version 9 opset_version 19
I Call acuity onnx optimize 'eliminate_option_const' success
/home/ss/aml_npu_sdk/acuity-toolkit/bin/acuitylib/acuitylib/onnx_ir/onnx_numpy_backend/ops/split.py:15: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
if inputs[1] == '':
W Call acuity onnx optimize 'froze_const_branch' fail, skip this optimize
I Call acuity onnx optimize 'froze_if' success
I Call acuity onnx optimize 'merge_sequence_construct_concat_from_sequence' success
I Call acuity onnx optimize 'merge_lrn_lowlevel_implement' success
[551892] Failed to execute script pegasus
Traceback (most recent call last):
File "pegasus.py", line 131, in <module>
File "pegasus.py", line 112, in main
File "acuitylib/app/importer/commands.py", line 245, in execute
File "acuitylib/vsi_nn.py", line 171, in load_onnx
File "acuitylib/app/importer/import_onnx.py", line 123, in run
File "acuitylib/converter/onnx/convert_onnx.py", line 61, in __init__
File "acuitylib/converter/onnx/convert_onnx.py", line 761, in _shape_inference
File "acuitylib/onnx_ir/onnx_numpy_backend/shape_inference.py", line 65, in infer_shape
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_graph_engine.py", line 70, in smart_onnx_scanner
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_node.py", line 48, in calc_and_assign_smart_info
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_toolkit.py", line 636, in multi_direction_broadcast_shape
ValueError: operands could not be broadcast together with shapes (1,0,160,160) (1,16,160,160)
Hello @afa1414 ,
It is the problem of PyTorch and ultralytics version. It is the same problem.

@Louis-Cheng-Liu
Thank you for the answer. I downloaded Ultralytics version 8.0.86, but I can’t see the head.py file as shown in the image. Do you know where it is?

Is the error ValueError: operands could not be broadcast together with shapes (1,0,160,160) (1,16,160,160) caused solely by version incompatibility?
Hello @afa1414 ,
A version of Ultralytics changes modules.py into modules folder. All functions in modules functions is in modules.py. Modify Detect and Pose class in modules.py.
The problem they solved by downgrading PyTorch and Ultralytics version. And the model in demo is generated by this version.
One thing
From output shape, i think your model may not be YOLO-pose.
@Louis-Cheng-Liu
The modules.py file contains the contents of the head file, so when I insert the same modifications I made earlier, the same error occurs.