Which system do you use? Android, Ubuntu, OOWOW or others?
**OOWOW to install Ubuntu 24.04 in my Khadas VIM 4**
Which version of system do you use? Please provide the version of the system here:
**Ubuntu 24.04**
Please describe your issue below:
I actually having issue running realtime text recognition (via KSNN) on Khadas Vim4, that’s on another issue, issue post #23238
Hence, I’m going to the C++ approach. The documentations says i can convert a pre-existing model in a separate enviroment using docker. I have followed the instruction in this link.
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
exec /bin/bash: exec format error
Post a console log of your issue below:
**WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
exec /bin/bash: exec format error**
DOCKER_RUN:docker run -it --name npu-vim4 --rm -v /home/khadas/vim4_npu_sdk:/home/khadas/npu -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro -v /home/root:/home/root numbqq/npu-vim4
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
exec /usr/bin/bash: exec format error
I’m able to convert the models into adla files using Intel based PC already. Thank you. However, as I am new to Computer vision, I’m still trying out stuff. I have converted this tflite model
into a mobilenetv2_int8.adla file. And transfer it to Khadas VIM4.
Then, i use this my converted adla file in one of the existing demo you guys provided.
**I replaced the adla file in the /data folder with the converted mobilenetv2_int8.adla.
adla usr space 1.2.0.5
the model is not compatible with the device
target device is r0p0, but platform device is r2p0
E NN_SDK:[aml_adla_create_network_common:357]Error: create network fail.
amlnn_init is fail
init_network fail.
I’m not sure what is r0p0 and r2p0. And I cant find it online.
Question:
Is it possible for you to guide me through how to create a realtime text recognition using Khadas VIM4 and Khadas IMX415 Camera? I understand that KSNN for VIM4 still under testing so I’m okay with the C++ approach. Below are some points.
I’m able to stream video feed from IMX415 to Khadas VIM4 via Gstreamer (C++).
I’m able to run the C++ Demos from vim4_npu_applications (even cap Demos, they are all working fine).
I’m able to convert the Demo Models from vim4_npu_sdk into adla files via Docker running a Linux Ubuntu environment in my Intel based Windows PC.
I don’t understand how to create a basic working realtime text recognition using custom adla models. (What is r0p0 r2p0, why some of the models, when i change the model width and height it’s not working properly. There’re so many questions and uncertainties).
I’ve been trying and experimenting with Khadas VIM4 for almost one month but got no result. I feel like it’s getting close but I really need some help.
Edit:
By the way, is it possible if i could get your contact so I can ask for support directly?
r0p0 and r2p0 are the different version device for Amlogic NPU. And VIM4 uses r2p0. Modify this parameter and convert tool will convert model which can infer in r2p0.
You can contact with me by this forum. I will deal with the problem on forum each working day. Or you can send an email for me. My email is louis.liu@wesion.com.
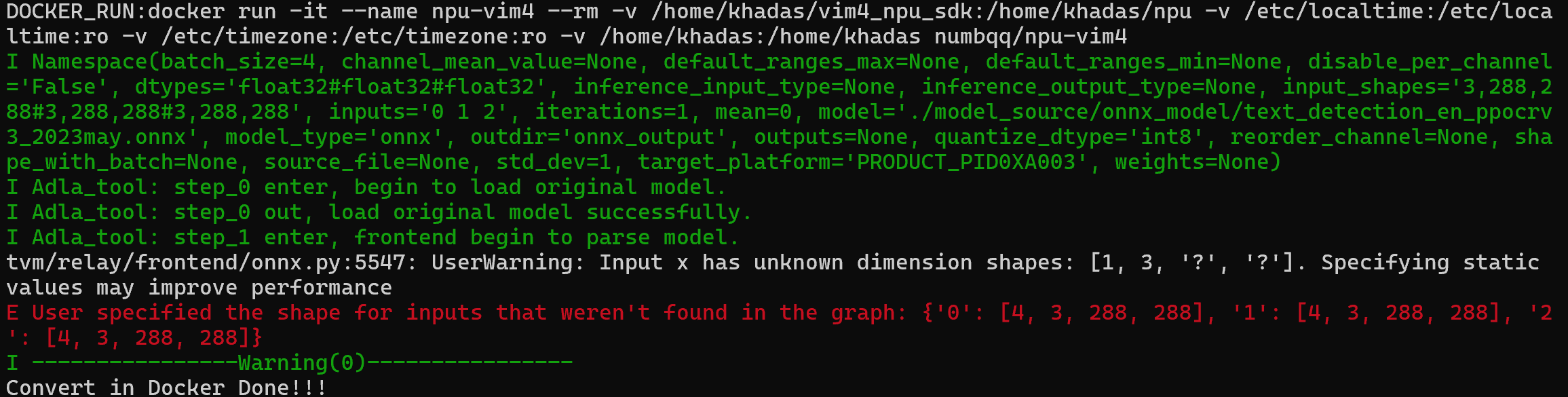
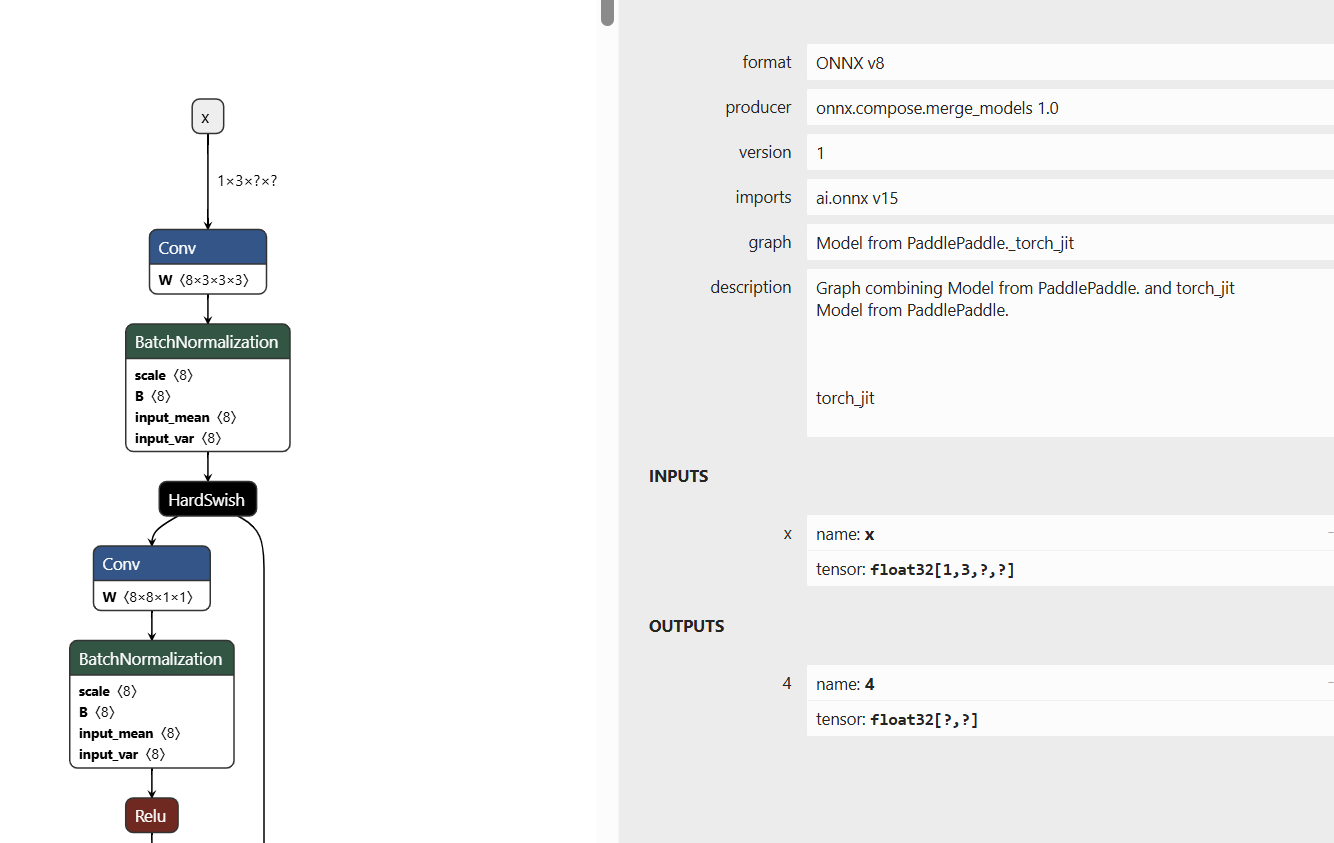
I don’t know what are the correct inputs. And what does graph mean?
Thank you so much for your email. Since you are frequent here, probably I will just contact you via this forum.
How about realtime text recognition? Now I’m trying out with the text detection and text recognition onnx file from OpenCV Zoo, convert them to adla files and run it in Khadas VIM4 via OpenCV C++. Is this approach workable?
I’m able to get the input-shape of the onnx file that i got from OpenCV Zoo using the code below:
from google.protobuf.json_format import MessageToDict
import onnx
model = onnx.load("text_detection_en_ppocrv3_2023may.onnx")
for _input in model.graph.input:
m_dict = MessageToDict(_input)
print(f"m_dict: {m_dict}")
dim_info = m_dict.get("type").get("tensorType").get("shape").get("dim")
print(f"dim_info: {dim_info}")
input_shape = [d.get("dimValue") for d in dim_info]
print(f"input_shape: {input_shape}")
Before get input to model, you should do preprocess for image. This operation is between reading image and model inferring. And normalization is a part of preprocess. In this demo, only has resize picture without normalization. So the normalization of this model is 0,0,0,1.
I see! Understood! How about the yolo_dataset.txt? I saw you did put iteration of 500 during the conversion to adla. Meaning, in your yolo_dataset.txt, there’re 500 images right? What images did you use?
When tool quantify model, it needs some images. The txt write in the paths of quantification image. The number of image has better between 200 and 500. And it is best to use pictures of the real using scene.
W:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model.
W:tensorflow:AutoGraph could not transform <function trace_model_call.<locals>._wrapped_model at 0x7f516da5d5e0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: Unable to locate the source code of <function trace_model_call.<locals>._wrapped_model at 0x7f516da5d5e0>. Note that functions defined in certain environments, like the interactive Python shell, do not expose their source code. If that is the case, you should define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.experimental.do_not_convert. Original error: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
2024-10-25 17:29:47.235116: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
W:tensorflow:AutoGraph could not transform <function canonicalize_signatures.<locals>.signature_wrapper at 0x7f506076bdc0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: Unable to locate the source code of <function canonicalize_signatures.<locals>.signature_wrapper at 0x7f506076bdc0>. Note that functions defined in certain environments, like the interactive Python shell, do not expose their source code. If that is the case, you should define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.experimental.do_not_convert. Original error: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
keras/utils/generic_utils.py:494: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument.
2024-10-25 17:30:01.090316: I tensorflow/core/grappler/devices.cc:75] Number of eligible GPUs (core count >= 8, compute capability >= 0.0): 0 (Note: TensorFlow was not compiled with CUDA or ROCm support)
2024-10-25 17:30:01.090651: I tensorflow/core/grappler/clusters/single_machine.cc:357] Starting new session
2024-10-25 17:30:01.131962: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:1137] Optimization results for grappler item: graph_to_optimize
function_optimizer: function_optimizer did nothing. time = 0.841ms.
function_optimizer: function_optimizer did nothing. time = 0.003ms.
2024-10-25 17:30:02.085136: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format.
2024-10-25 17:30:02.085182: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency.
2024-10-25 17:30:02.135113: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:210] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
2024-10-25 17:30:02.262048: I tensorflow/compiler/mlir/lite/flatbuffer_export.cc:1899] Estimated count of arithmetic ops: 5.169 G ops, equivalently 2.584 G MACs
I Quantize_info: rep_data_gen shape:[[1, 736, 736, 3]], source_file:yolo_dataset.txt,g_channel_mean_value:[[0.0, 0.0, 0.0, 1.0]]
2024-10-25 17:30:14.437926: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 3250176000 exceeds 10% of free system memory.
2024-10-25 17:30:16.024329: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 3250176000 exceeds 10% of free system memory.
E Expected bias tensor to be a vector.
It’s so frustrating that is so hard to set up a realtime ocr on Khadas VIM4. I’ll experiment on a Khadas VIM3 since there are more KSNN demos at the same time with VIM4.
W:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built. `model.compile_metrics` will be empty until you train or evaluate the model.
W:tensorflow:AutoGraph could not transform <function trace_model_call.<locals>._wrapped_model at 0x7fa71ef805e0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: Unable to locate the source code of <function trace_model_call.<locals>._wrapped_model at 0x7fa71ef805e0>. Note that functions defined in certain environments, like the interactive Python shell, do not expose their source code. If that is the case, you should define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.experimental.do_not_convert. Original error: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
2024-10-29 17:43:22.820304: W tensorflow/python/util/util.cc:348] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
W:tensorflow:AutoGraph could not transform <function canonicalize_signatures.<locals>.signature_wrapper at 0x7fa61052cdc0> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: Unable to locate the source code of <function canonicalize_signatures.<locals>.signature_wrapper at 0x7fa61052cdc0>. Note that functions defined in certain environments, like the interactive Python shell, do not expose their source code. If that is the case, you should define them in a .py source file. If you are certain the code is graph-compatible, wrap the call using @tf.autograph.experimental.do_not_convert. Original error: could not get source code
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
keras/utils/generic_utils.py:494: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument.
2024-10-29 17:43:47.661249: I tensorflow/core/grappler/devices.cc:75] Number of eligible GPUs (core count >= 8, compute capability >= 0.0): 0 (Note: TensorFlow was not compiled with CUDA or ROCm support)
2024-10-29 17:43:47.661847: I tensorflow/core/grappler/clusters/single_machine.cc:357] Starting new session
2024-10-29 17:43:47.738287: I tensorflow/core/grappler/optimizers/meta_optimizer.cc:1137] Optimization results for grappler item: graph_to_optimize
function_optimizer: function_optimizer did nothing. time = 0.844ms.
function_optimizer: function_optimizer did nothing. time = 0.003ms.
2024-10-29 17:43:49.374583: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:351] Ignored output_format.
2024-10-29 17:43:49.374704: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:354] Ignored drop_control_dependency.
2024-10-29 17:43:49.473043: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:210] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
2024-10-29 17:43:49.699902: I tensorflow/compiler/mlir/lite/flatbuffer_export.cc:1899] Estimated count of arithmetic ops: 5.169 G ops, equivalently 2.584 G MACs
I Quantize_info: rep_data_gen shape:[[1, 736, 736, 3]], source_file:yolo_dataset.txt,g_channel_mean_value:[[0.0, 0.0, 0.0, 1.0]]
2024-10-29 17:44:02.451959: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 3250176000 exceeds 10% of free system memory.
2024-10-29 17:44:05.227783: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 3250176000 exceeds 10% of free system memory.