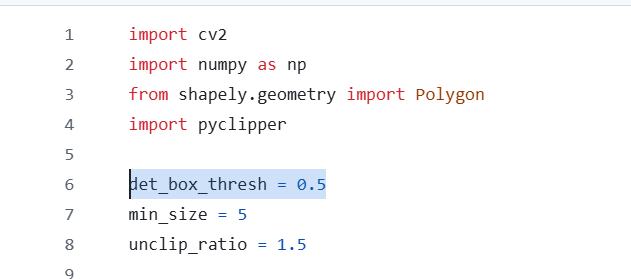
Hi @Louis-Cheng-Liu
- The below is the Python script in my Windows PC. I’ve imported the Paddle OCR Package and run it
import cv2
import numpy as np
import color_detection
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
# Also switch the language by modifying the lang parameter
ocr = PaddleOCR(lang="en") # The model file will be downloaded automatically when executed for the first time
cap = cv2.VideoCapture(0)
# cap.set(cv2.CAP_PROP_FRAME_WIDTH,2880)
# cap.set(cv2.CAP_PROP_FRAME_HEIGHT,1800)
if not cap.isOpened():
exit()
frame_counter = 0
while True:
ret,frame = cap.read()
w,h,c = frame.shape
print(ret)
if ret and w > 0 and h > 0:
frame_counter += 1
print(frame_counter)
# if frame_counter % 100 == 0:
# updateLiveUpdateToDb(camera_id)
# if frame_counter % 10 == 0:
result = ocr.ocr(frame)
# result = reader.readtext(frame)
for line in result:
print(line)
print(result)
# image = Image.open(frame).convert('RGB')
# print('result')
# print(result)
# boxes = [line[0] for line in result]
# txts = [line[1][0] for line in result]
# scores = [line[1][1] for line in result]
# im_show = draw_ocr(image, boxes, txts, scores)
# Image.fromarray(im_show)
for bboxtextprobtuplearray in result:
if bboxtextprobtuplearray is not None:
bbox = bboxtextprobtuplearray[0][0]
text = bboxtextprobtuplearray[0][1][0]
prob = bboxtextprobtuplearray[0][1][1]
print(f"Text: {text}")
print(f"Prob: {prob}")
if prob > 0.7:
top_left = bbox[0]
top_right = bbox[1]
bottom_right = bbox[2]
bottom_left = bbox[3]
if len(top_left) == 2 and len(top_right) == 2 and len(bottom_right) == 2 and len(bottom_left) == 2:
alphabet_image = frame[int(top_left[1]):int(bottom_left[1]),int(top_left[0]):int(top_right[0])]
result,result_mask,largest_pixel_count = color_detection.detect(alphabet_image)
color = (255, 255, 255)
if not result_mask is None:
if result == "red":
color = (0,0,255)
elif result == "yellow":
color = (0,255,255)
elif result == "blue":
color = (255,0,0)
elif result == "green":
color = (0,255,0)
cv2.putText(frame,f"{text},{result}",(int(top_left[0]),int(top_left[1] - 10)),cv2.FONT_HERSHEY_SIMPLEX,1,color,2)
else:
color = (255, 255, 255)
cv2.putText(frame,f"{text},None",(int(top_left[0]),int(top_left[1] - 10)),cv2.FONT_HERSHEY_SIMPLEX,1,color,2)
cv2.rectangle(frame,tuple(map(int, top_left)), tuple(map(int, bottom_right)),color,2)
# cv2.imshow("a",alphabet_image)
# else:
# img = np.zeros((100, 100, 3), dtype=np.uint8)
# cv2.imshow("a",img)
# print(f"Bbox: {bbox}")
# print(f"Text: {text} Probability: {prob}")
# if not result is None:
# writeResultToDb(camera_id,text,result)
# f = open(f"{result}.txt", "w")
# f.write(f"{text},{result}")
# f.close()
else:
frame = np.zeros((100, 100, 3), dtype=np.uint8)
cv2.imshow("Cam",frame)
if cv2.waitKey(1) == ord("q"):
break
cv2.destroyAllWindows()
I’m able to detect alphabets properly.
For Windows, in using my webcam.
Another thing, I also tried the EasyOCR Model, running on my Windows PC with NVIDIA, also running smoothly and able to detect the alphabets.
Another reason that we wish to use VIM4 is also it is more portable in classroom environments
-
Do you have YOLO demos for detecting single alphabet?
-
I’m using MIPI IMX 415 for Khadas VIM4
https://www.khadas.com/product-page/imx415-camera
-
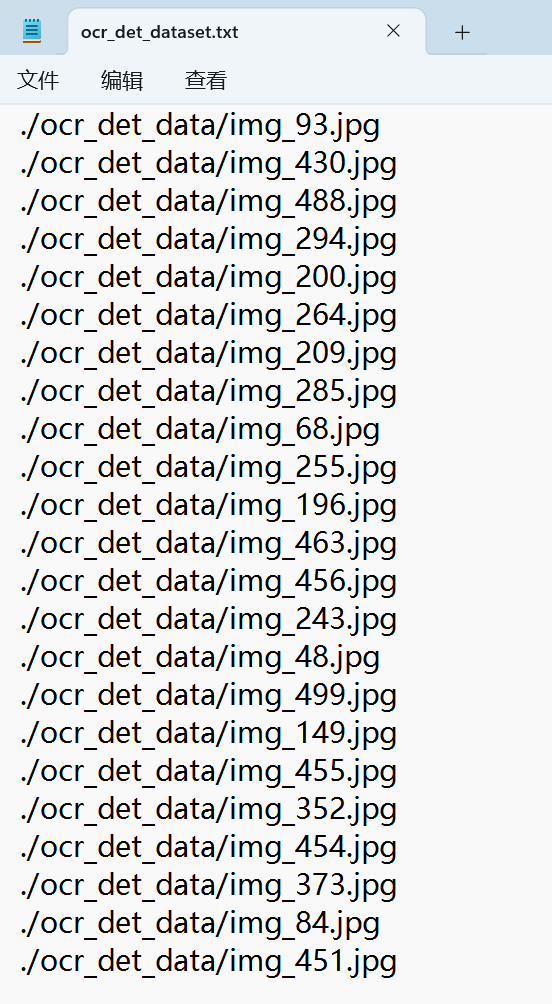
Another thing, the dataset in the KSNN convertion is in txt format. Does it mean i need to put the tesitng image file paths in txt file?
Does the format of the text file needs to be like this?