Hello, I am going to buy VIM3 or VIM4 for my deep learning project. It requires object detection and tracking from real-time video stream from the camera (At least 30fps). However, I have stuck with an issue of NPU performance. For VIM4 with NPU support, it is stated that:
" + Built-in 3.2 TOPS Performance NPU (only the NPU version comes with)"
And for VIM3:
+ Built-in 5 TOPS Performance NPU
On the other hand CPU and GPU performance are different (VIM4 wins):
Board
CPU
GPU
VIM4
61,597
82,388
VIM3
56,048
35,311
Can the obvious advantage in NPU TOPS for VIM3 be the main reason to use this board instead of VIM4 for deep learning? Are there other NPU benchmarks conducted which prove vice versa that VIM4 is better?
.
What kind of model are you planning to run, mobilenet, or YOLO series models?
I can share some sort of comparisons little later
Interms of raw compute, yes the VIM3 has the better performance, but there are factors that can limit peak performance such as the memory bandwidth of VIM3 compared to VIM4.
You will be able to run smaller models faster on the VIM3 with the onboard SRAM for storing weights but any time it will involve DDR memory transfer it will start to slow down.
VIM4 possess slightly better improvements in this domain, having better memory bandwidth (better for the NPU) , and improved CPU and GPU capabilities.
I think we can witness what is important for you with some tests and understanding your model scenario
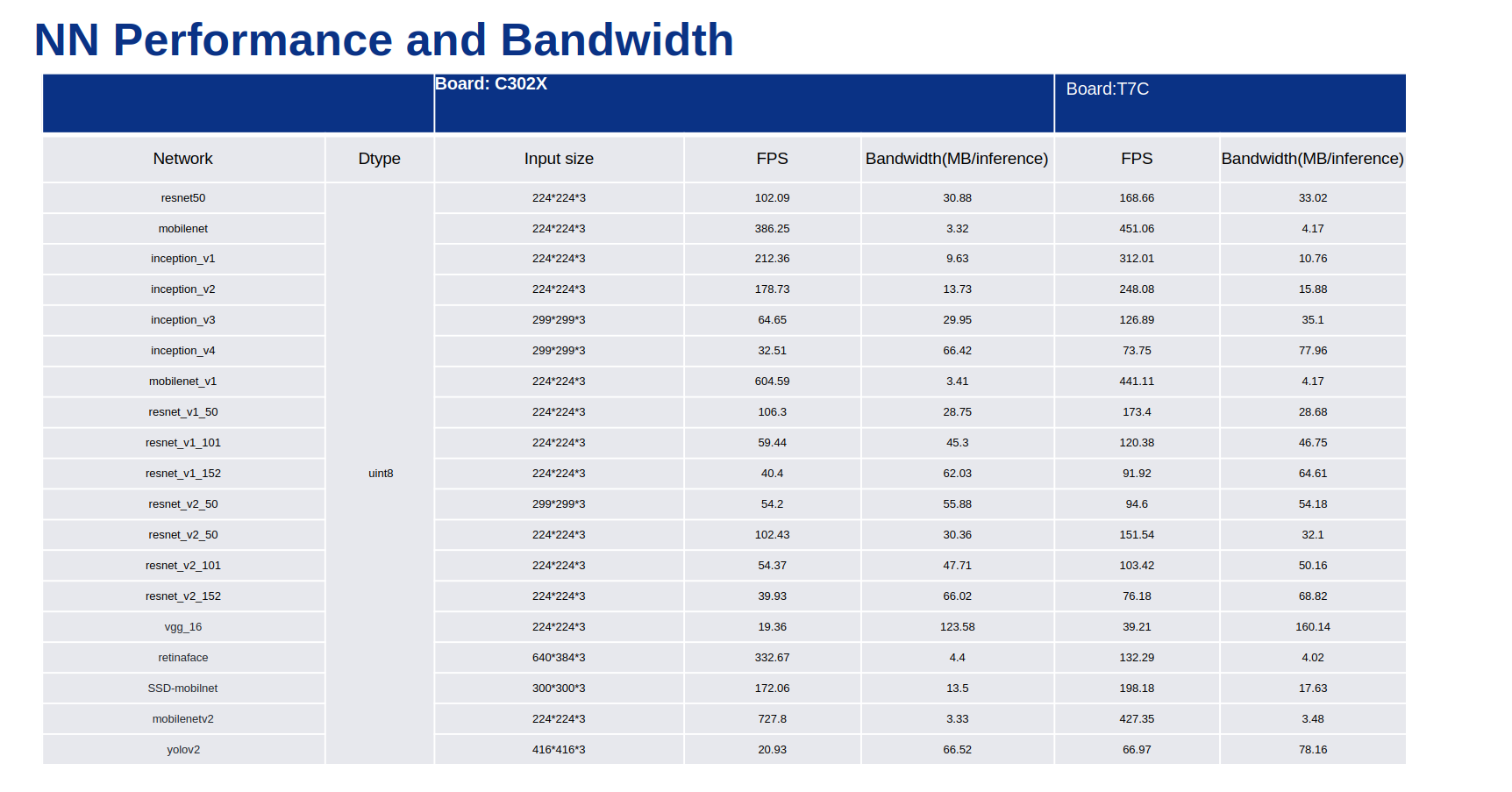
It will be very hard to achieve 30 FPS of inference with YOLO models, as even Edge2 with 6 TOPs can manage around ~10 FPS at best.
However, it is a different scenario with something like Mobilenet for image classification, as VIM3 itself can manage around magnitude of 100 FPS. It’s purely optimized for models that have more convolution.
For VIM4, Here is some benchmark provided by Amlogic themself (Under T7C table):