Which system do you use? Android, Ubuntu, OOWOW or others?
Ubuntu
Which version of system do you use? Khadas official images, self built images, or others?
Latest Khadas Ubuntu image installed with OOWOW
Please describe your issue below:
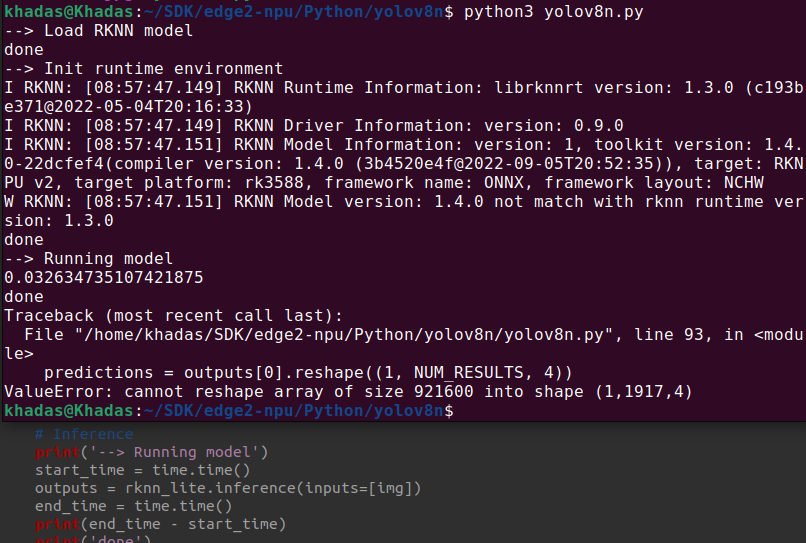
From NPU benchmarks of running YOLOv8n I expected to see each inference take ~100ms. When I perform inferences using the rknnlite api provided by RockChip I am seeing times that are at a minimum ~300ms.
start_time = time.time()
outputs = self.rknn_lite.inference(inputs=[frame])
end_time = time.time()
print(f"Inference duration: {end_time - start_time}")
This is measured exactly before and after the call to the RKNNLite detector object. self.rknn_lite is an instance of rknnlite.api.RKNNLite. I am using version 1.6.0 of the rknn wheel and librknnrt.so from the rknn-toolkit2 repository. The model I am using was created from the conversion script mentioned in the rknn model zoo repository. I am assuming that the yolov8n model in the edge2-npu repository is made in the same way with the only difference being the RKNN library version supported being 1.4.0 in the edge2 -npu repository.
During running I can see that my NPU load is only at about 20% across all 3 cores and my CPU is not loaded.