Hello @Yash_Bhagwat ,
I am very sorry that we do not have YOLOv8 segmentation demo now. We only have YOLOv8 detect demo.
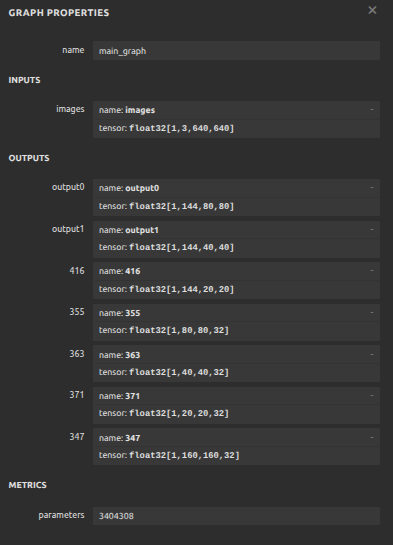
YOLOv8 seg model has three part outputs. First is box and conf information. Second is mask protos. The last is mask coefficients. Box and conf part is the same as YOLOv8 detect. You can refer our YOLOv8 doc to modify the code.
YOLOv8n KSNN Demo - 2 [Khadas Docs]
This is my modify seg code in ultralytics==8.0.86.
def forward(self, x):
"""Return model outputs and mask coefficients if training, otherwise return outputs and mask coefficients."""
p = self.proto(x[0]) # mask protos
bs = p.shape[0] # batch size
if torch.onnx.is_in_onnx_export():
p = p.permute(0, 2, 3, 1).unsqueeze(1)
mc = [self.cv4[i](x[i]).permute(0, 2, 3, 1).unsqueeze(1) for i in range(self.nl)]
x = self.detect(self, x)
return (x, tuple(mc), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
mc = torch.cat([self.cv4[i](x[i]).view(bs, self.nm, -1) for i in range(self.nl)], 2) # mask coefficients
x = self.detect(self, x)
if self.training:
return x, mc, p
return (torch.cat([x, mc], 1), p) if self.export else (torch.cat([x[0], mc], 1), (x[1], mc, p))
Use the code get model output like this.
Model convert command is the same as YOLOv8 detect.
For inferring on VIM3, preprocess is the same as detect model. For postprocess, box part is the same as detect. The rest part you can refer the official code to do by yourself.
If you meet any problem, you can ask me for help.