Does that mean when i train my model, i need to put the input shape as 960 width and 544 height?
Hi Louis,
Is it possible if i send you our training set?
Hello @JietChoo ,
About the model mistake, the problem is the model need more higher precision. The solution is add parameter disable-per-channel when convert rec model.
--model-name ppocr_rec
--model-type onnx
--model ./ppocr_rec.onnx
--inputs "x"
--input-shapes "3,48,320"
--dtypes "float32"
--quantize-dtype int16
--outdir onnx_output
--channel-mean-value "127.5,127.5,127.5,128"
--source-file ocr_rec_dataset.txt
--iterations 500
--batch-size 1
--kboard VIM4
--inference-input-type "float32"
--inference-output-type "float32"
--disable-per-channel False
You have better use 960×544 or multiples thereof training images. It can get the model more precise in this input size.
We have not train the model. We use the official model directly without training. We only have a quantifying images.
Hi Louis
I have tried this and have this error
|---+ KSNN Version: v1.4.1 +---|
Start init neural network ...
adla usr space 1.4.0.2
adla usr space 1.4.0.2
Done.
[API:aml_v4l2src_connect:271]Enter, devname : /dev/media0
func_name: aml_src_get_cam_method
initialize func addr: 0x7f889f167c
finalize func addr: 0x7f889f1948
start func addr: 0x7f889f199c
stop func addr: 0x7f889f1a4c
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 1, type 0x20000, name isp-csiphy), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 4, type 0x20000, name isp-adapter), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 7, type 0x20000, name isp-test-pattern-gen), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 9, type 0x20000, name isp-core), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 20, type 0x20001, name imx415-0), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 24, type 0x10001, name isp-ddr-input), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 28, type 0x10001, name isp-param), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 32, type 0x10001, name isp-stats), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 36, type 0x10001, name isp-output0), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 40, type 0x10001, name isp-output1), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 44, type 0x10001, name isp-output2), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 48, type 0x10001, name isp-output3), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id 52, type 0x10001, name isp-raw), ret 0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:235:carm_src_is_usb]carm_src_is_usb:info(id -2147483596, type 0x0, name ), ret -1
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:239:carm_src_is_usb]carm_src_is_usb:error Invalid argument
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:79:cam_src_select_socket]select socket:/tmp/camctrl0.socket
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:103:cam_src_obtain_devname]fork ok, pid:7304
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:103:cam_src_obtain_devname]fork ok, pid:0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camsrc.c:107:cam_src_obtain_devname]execl /usr/bin/camctrl
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:925:main][camctrl.cc:main:925]
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:889:parse_opt]media device name: /dev/media0
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:898:parse_opt]Server socket: /tmp/camctrl0.socket
Opening media device /dev/media0
Enumerating entities
Found 13 entities
Enumerating pads and links
mediaStreamInit[35]: mediaStreamInit ++.
mediaStreamInit[39]: media devnode: /dev/media0
mediaStreamInit[56]: ent 0, name isp-csiphy
mediaStreamInit[56]: ent 1, name isp-adapter
mediaStreamInit[56]: ent 2, name isp-test-pattern-gen
mediaStreamInit[56]: ent 3, name isp-core
mediaStreamInit[56]: ent 4, name imx415-0
mediaStreamInit[56]: ent 5, name isp-ddr-input
mediaStreamInit[56]: ent 6, name isp-param
mediaStreamInit[56]: ent 7, name isp-stats
mediaStreamInit[56]: ent 8, name isp-output0
mediaStreamInit[56]: ent 9, name isp-output1
mediaStreamInit[56]: ent 10, name isp-output2
mediaStreamInit[56]: ent 11, name isp-output3
mediaStreamInit[56]: ent 12, name isp-raw
mediaStreamInit[96]: get lens_ent fail
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video63 ok, fd 10
mediaStreamInit[151]: mediaStreamInit open video0 fd 10
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video64 ok, fd 11
mediaStreamInit[155]: mediaStreamInit open video1 fd 11
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video65 ok, fd 12
mediaStreamInit[159]: mediaStreamInit open video2 fd 12
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video66 ok, fd 13
mediaStreamInit[163]: mediaStreamInit open video3 fd 13
mediaStreamInit[172]: media stream init success
fetchPipeMaxResolution[27]: find matched sensor configs 3840x2160
media_set_wdrMode[420]: media_set_wdrMode ++ wdr_mode : 0
media_set_wdrMode[444]: media_set_wdrMode success --
media_set_wdrMode[420]: media_set_wdrMode ++ wdr_mode : 4
media_set_wdrMode[444]: media_set_wdrMode success --
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:374:link_and_activate_subdev]link and activate subdev successfully
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:407:media_stream_config]config media stream successfully
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video62 ok, fd 18
mediaLog[30]: VIDIOC_QUERYCAP: success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:172:check_capability]entity[isp-stats] -> video[/dev/video62], cap.driver:aml-camera, capabilities:0x85200001, device_caps:0x5200001
mediaLog[30]: v4l2_video_open: open subdev device node /dev/video61 ok, fd 19
mediaLog[30]: VIDIOC_QUERYCAP: success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:172:check_capability]entity[isp-param] -> video[/dev/video61], cap.driver:aml-camera, capabilities:0x85200001, device_caps:0x5200001
mediaLog[30]: set format ok, ret 0.
mediaLog[30]: set format ok, ret 0.
mediaLog[30]: request buf ok
mediaLog[30]: request buf ok
mediaLog[30]: query buffer success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:546:isp_alg_param_init]isp stats query buffer, length: 262144, offset: 0
mediaLog[30]: query buffer success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:546:isp_alg_param_init]isp stats query buffer, length: 262144, offset: 262144
mediaLog[30]: query buffer success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:546:isp_alg_param_init]isp stats query buffer, length: 262144, offset: 524288
mediaLog[30]: query buffer success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:546:isp_alg_param_init]isp stats query buffer, length: 262144, offset: 786432
mediaLog[30]: query buffer success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:568:isp_alg_param_init]isp param query buffer, length: 262144, offset: 0
alg2User func addr: 0x7fb26c8ed8
alg2Kernel func addr: 0x7fb26c8f08
algEnable func addr: 0x7fb26c8d70
algDisable func addr: 0x7fb26c8e90
algFwInterface func addr: 0x7fb26c9008
matchLensConfig[43]: LKK: fail to match lensConfig
cmos_get_ae_default_imx415[65]: cmos_get_ae_default
cmos_get_ae_default_imx415[116]: cmos_get_ae_default++++++
cmos_get_ae_default_imx415[65]: cmos_get_ae_default
cmos_get_ae_default_imx415[116]: cmos_get_ae_default++++++
aisp_enable[984]: tuning device not exist!
aisp_enable[987]: 3a commit b56e430e80b995bb88cecff66a3a6fc17abda2c7
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 16351232, 0, 0, 0
mediaLog[30]: streamon success
mediaLog[30]: streamon success
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:650:isp_alg_param_init]Finish initializing amlgorithm parameter ...
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:971:main]UNIX domain socket bound
[2025-02-14 07:04:11] DEBUG [amlv4l2src camctrl.cc:977:main]Accepting connections ...
[2025-02-14 07:04:12] DEBUG [amlv4l2src camsrc.c:122:cam_src_obtain_devname]udp_sock_create
[2025-02-14 07:04:12] DEBUG [amlv4l2src common/common.c:70:udp_sock_create][99219362][/tmp/camctrl0.socket] start connect
[2025-02-14 07:04:12] DEBUG [amlv4l2src camsrc.c:124:cam_src_obtain_devname]udp_sock_recv
[2025-02-14 07:04:12] DEBUG [amlv4l2src camctrl.cc:985:main]connected_sockfd: 21
[2025-02-14 07:04:12] DEBUG [amlv4l2src camctrl.cc:989:main]video_dev_name: /dev/video63
[2025-02-14 07:04:12] DEBUG [amlv4l2src camsrc.c:282:cam_src_initialize]obtain devname: /dev/video63
devname : /dev/video63
driver : aml-camera
device : Amlogic Camera Card
bus_info : platform:aml-cam
version : 331657
error tvin-port use -1
[API:aml_v4l2src_streamon:373]Enter
[2025-02-14 07:04:12] DEBUG [amlv4l2src camsrc.c:298:cam_src_start]start ...
[API:aml_v4l2src_streamon:376]Exit
[2025-02-14 07:04:12] DEBUG [amlv4l2src camctrl.cc:860:process_socket_thread]receive streamon notification
cmos_again_calc_table_imx415[125]: cmos_again_calc_table: 1836, 1836
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 11046912, 11046912, 11046912, 11046912
cmos_again_calc_table_imx415[125]: cmos_again_calc_table: 0, 0
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 14512128, 14512128, 14512128, 14512128
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13778944, 13778944, 13778944, 13778944
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13668352, 13668352, 13668352, 13668352
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13524992, 13524992, 13524992, 13524992
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13520896, 13520896, 13520896, 13520896
[ WARN:0@1.475] global ./modules/videoio/src/cap_gstreamer.cpp (1405) open OpenCV | GStreamer warning: Cannot query video position: status=0, value=-1, duration=-1
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13516800, 13516800, 13516800, 13516800
cmos_inttime_calc_table_imx415[150]: cmos_inttime_calc_table: 13512704, 13512704, 13512704, 13512704
[2025-02-14 07:04:12] DEBUG [amlv4l2src camctrl.cc:914:Signalhandler]enter camctrl Signalhandler: 15
[2025-02-14 07:04:12] DEBUG [amlv4l2src camctrl.cc:917:Signalhandler]exit camctrl Signalhandler: 15
Segmentation fault
My Code
ppocr-cap-960-544.py
import numpy as np
import os
import urllib.request
import argparse
import sys
import math
from ksnn.api import KSNN
from ksnn.types import *
import cv2 as cv
import time
from postprocess import ocr_det_postprocess, ocr_rec_postprocess
from PIL import Image, ImageDraw, ImageFont
det_mean = [123.675, 116.28, 103.53]
det_var = [255 * 0.229, 255 * 0.224, 255 * 0.225]
rec_mean = 127.5
rec_var = 128
det_input_size = (544, 960) # (model height, model width)
rec_input_size = ( 48, 320) # (model height, model width)
# rec_output_size = (40, 6625)
rec_output_size = (40, 97)
font = ImageFont.truetype("./data/simfang.ttf", 20)
def draw(image, boxes):
draw_img = Image.fromarray(image)
draw = ImageDraw.Draw(draw_img)
for box in boxes:
x1, y1, x2, y2, score, text = box
left = max(0, np.floor(x1 + 0.5).astype(int))
top = max(0, np.floor(y1 + 0.5).astype(int))
right = min(image.shape[1], np.floor(x2 + 0.5).astype(int))
bottom = min(image.shape[0], np.floor(y2 + 0.5).astype(int))
draw.rectangle((left, top, right, bottom), outline=(0, 255, 0), width=2)
draw.text((left, top - 20), text, font=font, fill=(0, 255, 0))
return draw_img, np.array(draw_img)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--det_library", help="Path to C static library file for ppocr_det")
parser.add_argument("--det_model", help="Path to nbg file for ppocr_det")
parser.add_argument("--rec_library", help="Path to C static library file for ppocr_rec")
parser.add_argument("--rec_model", help="Path to nbg file for ppocr_rec")
parser.add_argument("--device", help="the number for video device")
parser.add_argument("--level", help="Information printer level: 0/1/2")
args = parser.parse_args()
if args.det_model :
if os.path.exists(args.det_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.det_model))
det_model = args.det_model
else :
sys.exit("NBG file not found !!! Please use format: --det_model")
if args.rec_model :
if os.path.exists(args.rec_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.rec_model))
rec_model = args.rec_model
else :
sys.exit("NBG file not found !!! Please use format: --rec_model")
if args.device :
cap_num = args.device
else :
sys.exit("video device not found !!! Please use format :--device ")
if args.det_library :
if os.path.exists(args.det_library) == False:
sys.exit('ppocr_det C static library \'{}\' not exist'.format(args.det_library))
det_library = args.det_library
else :
sys.exit("ppocr_det C static library not found !!! Please use format: --det_library")
if args.rec_library :
if os.path.exists(args.rec_library) == False:
sys.exit('ppocr_rec C static library \'{}\' not exist'.format(args.rec_library))
rec_library = args.rec_library
else :
sys.exit("ppocr_rec C static library not found !!! Please use format: --rec_library")
if args.level == '1' or args.level == '2' :
level = int(args.level)
else :
level = 0
ppocr_det = KSNN('VIM4')
ppocr_rec = KSNN('VIM4')
print(' |---+ KSNN Version: {} +---| '.format(ppocr_det.get_nn_version()))
print('Start init neural network ...')
ppocr_det.nn_init(library=det_library, model=det_model, level=level)
ppocr_rec.nn_init(library=rec_library, model=rec_model, level=level)
print('Done.')
# usb camera
# cap = cv.VideoCapture(int(cap_num))
# mipi
pipeline = "v4l2src device=/dev/media0 io-mode=dmabuf ! queue ! video/x-raw,format=YUY2,framerate=30/1 ! queue ! videoconvert ! appsink"
cap = cv.VideoCapture(pipeline, cv.CAP_GSTREAMER)
# cap.set(3,1920)
# cap.set(4,1080)
while(1):
ret,orig_img = cap.read()
start = time.time()
det_img = cv.resize(orig_img, (det_input_size[1], det_input_size[0])).astype(np.float32)
det_img[:, :, 0] = (det_img[:, :, 0] - det_mean[0]) / det_var[0]
det_img[:, :, 1] = (det_img[:, :, 1] - det_mean[1]) / det_var[1]
det_img[:, :, 2] = (det_img[:, :, 2] - det_mean[2]) / det_var[2]
det_output = ppocr_det.nn_inference(det_img, input_shape=(det_input_size[0], det_input_size[1], 3), input_type="RAW", output_shape=[(det_input_size[0], det_input_size[1], 1)], output_type="FLOAT")
det_results = ocr_det_postprocess(det_output[0], orig_img, det_input_size)
final_results = []
for i in range(len(det_results)):
xmin, ymin, xmax, ymax, _, _ = det_results[i]
rec_img = orig_img[ymin:ymax, xmin:xmax]
new_height = rec_input_size[0]
new_width = int(new_height / rec_img.shape[0] * rec_img.shape[1])
if new_width > rec_input_size[1] * 1.2:
# text too long. If you want to detect it, please convert rec model input longer.
continue
elif new_width < rec_input_size[1] * 1.2 and new_width > rec_input_size[1]:
new_width = rec_input_size[1]
rec_img = cv.resize(rec_img, (new_width, new_height)).astype(np.float32)
padding_img = np.zeros((rec_input_size[0], rec_input_size[1], 3)).astype(np.float32)
padding_img[:, :new_width] = rec_img
padding_img = (padding_img - rec_mean) / rec_var
rec_output = ppocr_rec.nn_inference(padding_img, input_shape=(rec_input_size[0], rec_input_size[1], 3), input_type="RAW", output_shape=[(rec_output_size[0], rec_output_size[1])], output_type="FLOAT")
det_results[i][5] = ocr_rec_postprocess(rec_output[0])
final_results.append(det_results[i])
if det_results is not None:
pil_img, cv_img = draw(orig_img, final_results)
cv_img = cv.resize(cv_img, (1280, 720))
end = time.time()
print('Done. inference time: ', end - start)
cv.imshow("capture", cv_img)
if cv.waitKey(1) & 0xFF == ord('q'):
break
ppocr_det.nn_destory_network()
ppocr_rec.nn_destory_network()
cap.release()
cv.destroyAllWindows()
Nevermind, Im able to run the code with 960-544 script. However I’m still detecting chinese characters

import numpy as np
import os
import urllib.request
import argparse
import sys
import math
from ksnn.api import KSNN
from ksnn.types import *
import cv2 as cv
import time
from postprocess import ocr_det_postprocess, ocr_rec_postprocess
from PIL import Image, ImageDraw, ImageFont
from initialize_firebase_credentials import initializeFirebaseCredentials
from update_live_update_to_db import updateLiveUpdateToDb
from write_result_to_db import writeResultToDb
import color_detection
initializeFirebaseCredentials()
det_mean = [123.675, 116.28, 103.53]
det_var = [255 * 0.229, 255 * 0.224, 255 * 0.225]
rec_mean = 127.5
rec_var = 128
det_input_size = (544, 960) # (model height, model width)
rec_input_size = ( 48, 320) # (model height, model width)
# rec_output_size = (40, 6625)
rec_output_size = (40, 97)
font = ImageFont.truetype("./data/simfang.ttf", 20)
texts_data = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"1","2","3","4","5","6","7","8","9","0","+","-","×","÷"
]
def draw(image, boxes):
draw_img = Image.fromarray(image)
draw = ImageDraw.Draw(draw_img)
for box in boxes:
x1, y1, x2, y2, score, text = box
left = max(0, np.floor(x1 + 0.5).astype(int))
top = max(0, np.floor(y1 + 0.5).astype(int))
right = min(image.shape[1], np.floor(x2 + 0.5).astype(int))
bottom = min(image.shape[0], np.floor(y2 + 0.5).astype(int))
color = (255,255,255)
alphabet_image = image[int(left):int(right),int(top):int(bottom)]
color_result = "N/A"
if np.sum(alphabet_image) != 0:
result,result_mask,largest_pixel_count = color_detection.detect(alphabet_image)
if not result_mask is None:
color_result = result
if result == "red":
color = (0,0,255)
elif result == "yellow":
color = (0,255,255)
elif result == "blue":
color = (255,0,0)
elif result == "green":
color = (0,255,0)
draw.rectangle((left, top, right, bottom), outline=color, width=2)
draw.text((left, top - 20), f"{text}, {color_result}", font=font, fill=color)
return draw_img, np.array(draw_img)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--det_library", help="Path to C static library file for ppocr_det")
parser.add_argument("--det_model", help="Path to nbg file for ppocr_det")
parser.add_argument("--rec_library", help="Path to C static library file for ppocr_rec")
parser.add_argument("--rec_model", help="Path to nbg file for ppocr_rec")
parser.add_argument("--device", help="the number for video device")
parser.add_argument("--level", help="Information printer level: 0/1/2")
args = parser.parse_args()
if args.det_model :
if os.path.exists(args.det_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.det_model))
det_model = args.det_model
else :
sys.exit("NBG file not found !!! Please use format: --det_model")
if args.rec_model :
if os.path.exists(args.rec_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.rec_model))
rec_model = args.rec_model
else :
sys.exit("NBG file not found !!! Please use format: --rec_model")
if args.device :
cap_num = args.device
else :
sys.exit("video device not found !!! Please use format :--device ")
if args.det_library :
if os.path.exists(args.det_library) == False:
sys.exit('ppocr_det C static library \'{}\' not exist'.format(args.det_library))
det_library = args.det_library
else :
sys.exit("ppocr_det C static library not found !!! Please use format: --det_library")
if args.rec_library :
if os.path.exists(args.rec_library) == False:
sys.exit('ppocr_rec C static library \'{}\' not exist'.format(args.rec_library))
rec_library = args.rec_library
else :
sys.exit("ppocr_rec C static library not found !!! Please use format: --rec_library")
if args.level == '1' or args.level == '2' :
level = int(args.level)
else :
level = 0
ppocr_det = KSNN('VIM4')
ppocr_rec = KSNN('VIM4')
print(' |---+ KSNN Version: {} +---| '.format(ppocr_det.get_nn_version()))
print('Start init neural network ...')
ppocr_det.nn_init(library=det_library, model=det_model, level=level)
ppocr_rec.nn_init(library=rec_library, model=rec_model, level=level)
print('Done.')
# usb camera
# cap = cv.VideoCapture(int(cap_num))
# mipi
pipeline = "v4l2src device=/dev/media0 io-mode=dmabuf ! queue ! video/x-raw,format=YUY2,framerate=30/1 ! queue ! videoconvert ! appsink"
cap = cv.VideoCapture(pipeline, cv.CAP_GSTREAMER)
cap.set(3,1920)
cap.set(4,1080)
frame_counter = 0;
camera_id = "XzWz75mg6ZKB3S28QedR"
while(1):
if frame_counter % 100 == 0:
updateLiveUpdateToDb(camera_id)
frame_counter += 1
ret,orig_img = cap.read()
start = time.time()
det_img = cv.resize(orig_img, (det_input_size[1], det_input_size[0])).astype(np.float32)
det_img[:, :, 0] = (det_img[:, :, 0] - det_mean[0]) / det_var[0]
det_img[:, :, 1] = (det_img[:, :, 1] - det_mean[1]) / det_var[1]
det_img[:, :, 2] = (det_img[:, :, 2] - det_mean[2]) / det_var[2]
det_output = ppocr_det.nn_inference(det_img, input_shape=(det_input_size[0], det_input_size[1], 3), input_type="RAW", output_shape=[(det_input_size[0], det_input_size[1], 1)], output_type="FLOAT")
det_results = ocr_det_postprocess(det_output[0], orig_img, det_input_size)
final_results = []
for i in range(len(det_results)):
xmin, ymin, xmax, ymax, _, _ = det_results[i]
rec_img = orig_img[ymin:ymax, xmin:xmax]
new_height = rec_input_size[0]
new_width = int(new_height / rec_img.shape[0] * rec_img.shape[1])
if new_width > rec_input_size[1] * 1.2:
# text too long. If you want to detect it, please convert rec model input longer.
continue
elif new_width < rec_input_size[1] * 1.2 and new_width > rec_input_size[1]:
new_width = rec_input_size[1]
rec_img = cv.resize(rec_img, (new_width, new_height)).astype(np.float32)
padding_img = np.zeros((rec_input_size[0], rec_input_size[1], 3)).astype(np.float32)
padding_img[:, :new_width] = rec_img
padding_img = (padding_img - rec_mean) / rec_var
rec_output = ppocr_rec.nn_inference(padding_img, input_shape=(rec_input_size[0], rec_input_size[1], 3), input_type="RAW", output_shape=[(rec_output_size[0], rec_output_size[1])], output_type="FLOAT")
det_results[i][5] = ocr_rec_postprocess(rec_output[0])
print('results')
print(det_results[i])
probability = det_results[i][4]
text = det_results[i][5]
print(f'probability: {probability}')
print(f'text: {text}')
print(f'text length: {len(text)}')
final_results.append(det_results[i])
# if len(text) == 1 and probability > 0.5 and text in texts_data:
# final_results.append(det_results[i])
if det_results is not None:
pil_img, cv_img = draw(orig_img, final_results)
cv_img = cv.resize(cv_img, (1280, 720))
end = time.time()
print('Done. inference time: ', end - start)
cv.imshow("capture", cv_img)
if cv.waitKey(1) & 0xFF == ord('q'):
break
ppocr_det.nn_destory_network()
ppocr_rec.nn_destory_network()
cap.release()
cv.destroyAllWindows()
Hello @JietChoo ,
Have you modify the postprocess dict txt path?
character_str = ["blank"]
-with open("./data/ppocr_keys_v1.txt", "rb") as fin:
+with open("./data/en_dict.txt", "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode("utf-8").strip("\n").strip("\r\n")
character_str.append(line)
character_str.append(" ")
ignored_token = [0]
Dear Louis,
We have trained a model from scratch, just detecting the “+” symbol. When we run the det and rec model on PPOCR itself (On my Windows) it works fine. Now, after i convert to onnx and to ksnn, it cannot detect anything. Can you help me out?
I’ll have sent you my det and rec ppocr files
Dear Louis
Really hope to hear from you soon as this is super urgent from our side
Dear Louis,
Any update on your side?
Hello @JietChoo ,
Sorry for late. We convert your model and infer on VIM4, but everything is right.
Here are our parameters.
# det
--model-name ppocr_det
--model-type onnx
--model ./ppocr_det.onnx
--inputs "x"
--input-shapes "3,544,960"
--dtypes "float32"
--quantize-dtype int8
--outdir onnx_output
--channel-mean-value "123.675,116.28,103.53,57.375"
--source-file ocr_det_dataset.txt
--iterations 500
--batch-size 1
--kboard VIM4
--inference-input-type "float32"
--inference-output-type "float32"
# rec
--model-name ppocr_rec
--model-type onnx
--model ./ppocr_rec.onnx
--inputs "x"
--input-shapes "3,48,320"
--dtypes "float32"
--quantize-dtype int16
--outdir onnx_output
--channel-mean-value "127.5,127.5,127.5,128"
--source-file ocr_rec_dataset.txt
--iterations 500
--batch-size 1
--kboard VIM4
--inference-input-type "float32"
--inference-output-type "float32"
--disable-per-channel False

Your rec model class has changed. The model output has 6 class, remember modify en_dict.txt to your class txt and output shape rec_output_size = (40, 6)
Dear Louis,
Thank you for your reply. How do you determine what config to set? As in what to put in the ksnn_args. And by rec_output_size, where and how to do determine it?
This is because we are planning to train A-Z,a-z,0-9,+ - × ÷ ✓ X. So we are not sure whether the configs will change later on
We are aware 0 O o and X x × might be similar so we will handle those in the application side
Hello @JietChoo ,
A easy method for you. Change the ONNX model to a fixed input size and then use Netron open the model getting the output size.
python3 -m paddle2onnx.optimize --input_model inference/det_onnx/model.onnx \
--output_model inference/det_onnx/model.onnx \
--input_shape_dict "{'x': [1,3,48,320]}"
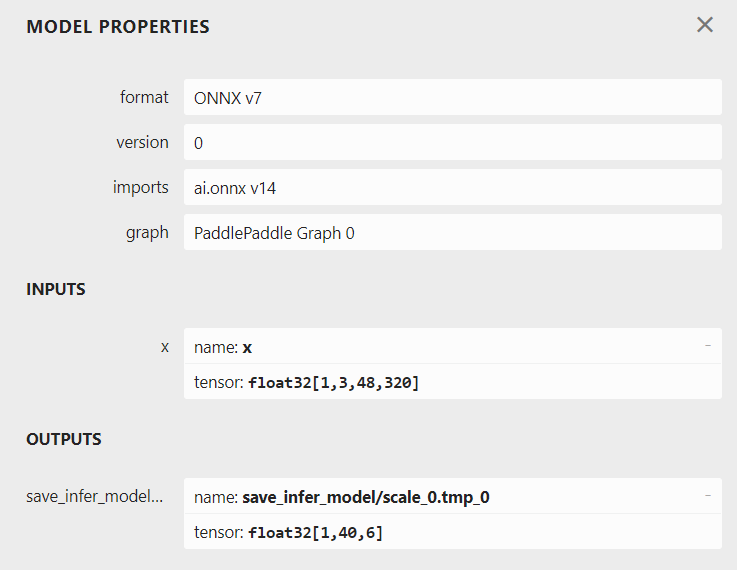
Thank you, i will try it out.
By the way, the rec_output_size = (40, 6) is in the postprocess file is it?

Hi Louis, we have tried converting with the ksnn_args you provided, still cant detect. I’ll send over the converted files to you via email
Hello @JietChoo ,
Could you provide your demo code? I use your model that can infer right result.
Hi,
Do you mean demo for Paddle OCR that runs on my Windows or the code for Vim4?
The below is the main.py
import cv2
from paddleocr import PaddleOCR,draw_ocr
import color_detection
# Paddleocr supports Chinese, English, French, German, Korean and Japanese.
# You can set the parameter `lang` as `ch`, `en`, `fr`, `german`, `korean`, `japan`
# to switch the language model in order.
ocr = PaddleOCR(use_angle_cls=True,lang='en',rec_model_dir='./my_rec',det_model_dir='./my_det',
rec_char_dict_path='./dict/en_dict_custom_symbol.txt'
) # need to run only once to download and load model into memory
cap = cv2.VideoCapture(0)
# cap.set(cv2.CAP_PROP_FRAME_WIDTH,2880)
# cap.set(cv2.CAP_PROP_FRAME_HEIGHT,1800)
if not cap.isOpened():
exit()
frame_counter = 0
while True:
ret,frame = cap.read()
if ret:
w,h,c = frame.shape
if w > 0 and h > 0:
result = ocr.ocr(frame)
print(result)
for bbox_text_prob_tuple_array in result:
if bbox_text_prob_tuple_array is not None:
for bbox_text_prob_tuple in bbox_text_prob_tuple_array:
bbox = bbox_text_prob_tuple[0]
text = bbox_text_prob_tuple[1][0]
prob = bbox_text_prob_tuple[1][1]
print(f"Text: {text}")
print(f"Prob: {prob}")
if prob > 0.5:
top_left = bbox[0]
top_right = bbox[1]
bottom_right = bbox[2]
bottom_left = bbox[3]
if len(top_left) == 2 and len(top_right) == 2 and len(bottom_right) == 2 and len(bottom_left) == 2:
alphabet_image = frame[int(top_left[1]):int(bottom_left[1]),int(top_left[0]):int(top_right[0])]
if alphabet_image.shape[0] > 0 and alphabet_image.shape[1] > 0:
result,result_mask,largest_pixel_count = color_detection.detect(alphabet_image)
color = (255, 255, 255)
if not result_mask is None:
if result == "red":
color = (0,0,255)
elif result == "yellow":
color = (0,255,255)
elif result == "blue":
color = (255,0,0)
elif result == "green":
color = (0,255,0)
cv2.putText(frame,f"{text},{result}",(int(top_left[0]),int(top_left[1] - 10)),cv2.FONT_HERSHEY_SIMPLEX,1,color,2)
else:
color = (255, 255, 255)
cv2.putText(frame,f"{text},None",(int(top_left[0]),int(top_left[1] - 10)),cv2.FONT_HERSHEY_SIMPLEX,1,color,2)
cv2.rectangle(frame,tuple(map(int, top_left)), tuple(map(int, bottom_right)),color,2)
# cv2.imshow("a",alphabet_image)
# else:
# img = np.zeros((100, 100, 3), dtype=np.uint8)
# cv2.imshow("a",img)
# print(f"Bbox: {bbox}")
# print(f"Text: {text} Probability: {prob}")
# if not result is None:
# writeResultToDb(camera_id,text,result)
# f = open(f"{result}.txt", "w")
# f.write(f"{text},{result}")
# f.close()
cv2.imshow("Cam",frame)
if cv2.waitKey(1) == ord("q"):
break
cv2.destroyAllWindows()
# draw result
# from PIL import Image
# result = result[0]
# image = Image.open(img_path).convert('RGB')
# boxes = [line[0] for line in result]
# txts = [line[1][0] for line in result]
# scores = [line[1][1] for line in result]
# im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
# im_show = Image.fromarray(im_show)
# im_show.save('result.jpg')
color_detection.py
# Python code for Multiple Color Detection
import numpy as np
import cv2
import color_utils
# Capturing video through webcam
webcam = cv2.VideoCapture(0)
# Start a while loop
def detect(image_frame):
# Convert the imageFrame in
# BGR(RGB color space) to
# HSV(hue-saturation-value)
# color space
hsv_frame = cv2.cvtColor(image_frame, cv2.COLOR_BGR2HSV)
# Set range for red color and
# define mask
red_lower = color_utils.lower_red
red_upper = color_utils.upper_red
red_mask = cv2.inRange(hsv_frame, red_lower, red_upper)
# Set range for yellow color and
# define mask
yellow_lower = color_utils.lower_yellow
yellow_upper = color_utils.upper_yellow
yellow_mask = cv2.inRange(hsv_frame, yellow_lower, yellow_upper)
# Set range for blue color and
# define mask
blue_lower = color_utils.lower_blue
blue_upper = color_utils.upper_blue
blue_mask = cv2.inRange(hsv_frame, blue_lower, blue_upper)
# Set range for green color and
# define mask
green_lower = color_utils.lower_green
green_upper = color_utils.upper_green
green_mask = cv2.inRange(hsv_frame, green_lower, green_upper)
red_pixels = np.where(red_mask[red_mask==255])
yellow_pixels = np.where(yellow_mask[yellow_mask == 255])
blue_pixels = np.where(blue_mask[blue_mask == 255])
green_pixels = np.where(green_mask[red_mask == 255])
w,h,c = hsv_frame.shape
total_pixel_count = w * h
red_pixel_count = red_pixels[0].__array__().__len__()
yellow_pixel_count = yellow_pixels[0].__array__().__len__()
blue_pixel_count = blue_pixels[0].__array__().__len__()
green_pixel_count = green_pixels[0].__array__().__len__()
result = None
result_mask = None
largest_pixel_count = 0
if red_pixel_count > largest_pixel_count:
largest_pixel_count = red_pixel_count
result_mask = red_mask
result = "red"
if yellow_pixel_count > largest_pixel_count:
largest_pixel_count = yellow_pixel_count
result_mask = yellow_mask
result = "yellow"
if blue_pixel_count > largest_pixel_count:
largest_pixel_count = blue_pixel_count
result_mask = blue_mask
result = "blue"
if green_pixel_count > largest_pixel_count:
largest_pixel_count = green_pixel_count
result_mask = green_mask
result = "green"
percentage_on_mask = largest_pixel_count / total_pixel_count
print(f"Pre Result: {result}")
print(f"Largest Pixel Count: {largest_pixel_count}")
print(f"Total Pixel Count: {total_pixel_count}")
print(f"Percentage on mask {percentage_on_mask}")
if percentage_on_mask < 0.02:
largest_pixel_count = 0
result_mask = None
result = None
return [result,result_mask,largest_pixel_count]
color_utils.py
import numpy as np
lower_red = np.array([0,100,100], np.uint8)
upper_red = np.array([10,255,255], np.uint8)
lower_yellow = np.array([15, 0, 0], np.uint8)
upper_yellow = np.array([36, 255, 255], np.uint8)
lower_blue = np.array([100,150,0], np.uint8)
upper_blue = np.array([110,255,255], np.uint8)
lower_green = np.array([36,0,0], np.uint8)
upper_green = np.array([86,255,255], np.uint8)
The above is the code that i ran on Windows and Nvidia GPU. I have sent the models via email to you
Hello @JietChoo ,
I mean the code on VIM4.Because i use your nb model infer on VIM4 that can get right result.
Alright! The below are my codes
ppocr-cap-960-544.py
import numpy as np
import os
import urllib.request
import argparse
import sys
import math
from ksnn.api import KSNN
from ksnn.types import *
import cv2 as cv
import time
from postprocess import ocr_det_postprocess, ocr_rec_postprocess
from PIL import Image, ImageDraw, ImageFont
from write_result_to_db import writeResultToDb
import color_detection
det_mean = [123.675, 116.28, 103.53]
det_var = [255 * 0.229, 255 * 0.224, 255 * 0.225]
rec_mean = 127.5
rec_var = 128
det_input_size = (544, 960) # (model height, model width)
rec_input_size = ( 48, 320) # (model height, model width)
# rec_output_size = (40, 6625)
# rec_output_size = (40, 97)
rec_output_size = (40, 6)
font = ImageFont.truetype("./data/simfang.ttf", 20)
texts_data = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z",
"A","B","C","D","E","F","G","H","I","J","K","L","M","N","O","P","Q","R","S","T","U","V","W","X","Y","Z",
"1","2","3","4","5","6","7","8","9","0","+","-","×","÷"
]
def draw(image, boxes):
draw_img = Image.fromarray(image)
draw = ImageDraw.Draw(draw_img)
for box in boxes:
x1, y1, x2, y2, score, text = box
left = max(0, np.floor(x1 + 0.5).astype(int))
top = max(0, np.floor(y1 + 0.5).astype(int))
right = min(image.shape[1], np.floor(x2 + 0.5).astype(int))
bottom = min(image.shape[0], np.floor(y2 + 0.5).astype(int))
color = (255,255,255)
alphabet_image = image[int(left):int(right),int(top):int(bottom)]
color_result = "N/A"
if np.sum(alphabet_image) != 0:
result,result_mask,largest_pixel_count = color_detection.detect(alphabet_image)
if not result_mask is None:
color_result = result
if result == "red":
color = (0,0,255)
elif result == "yellow":
color = (0,255,255)
elif result == "blue":
color = (255,0,0)
elif result == "green":
color = (0,255,0)
draw.rectangle((left, top, right, bottom), outline=color, width=2)
draw.text((left, top - 20), f"{text}, {color_result}", font=font, fill=color)
return draw_img, np.array(draw_img)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--det_library", help="Path to C static library file for ppocr_det")
parser.add_argument("--det_model", help="Path to nbg file for ppocr_det")
parser.add_argument("--rec_library", help="Path to C static library file for ppocr_rec")
parser.add_argument("--rec_model", help="Path to nbg file for ppocr_rec")
parser.add_argument("--device", help="the number for video device")
parser.add_argument("--level", help="Information printer level: 0/1/2")
args = parser.parse_args()
if args.det_model :
if os.path.exists(args.det_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.det_model))
det_model = args.det_model
else :
sys.exit("NBG file not found !!! Please use format: --det_model")
if args.rec_model :
if os.path.exists(args.rec_model) == False:
sys.exit('ppocr_det Model \'{}\' not exist'.format(args.rec_model))
rec_model = args.rec_model
else :
sys.exit("NBG file not found !!! Please use format: --rec_model")
if args.device :
cap_num = args.device
else :
sys.exit("video device not found !!! Please use format :--device ")
if args.det_library :
if os.path.exists(args.det_library) == False:
sys.exit('ppocr_det C static library \'{}\' not exist'.format(args.det_library))
det_library = args.det_library
else :
sys.exit("ppocr_det C static library not found !!! Please use format: --det_library")
if args.rec_library :
if os.path.exists(args.rec_library) == False:
sys.exit('ppocr_rec C static library \'{}\' not exist'.format(args.rec_library))
rec_library = args.rec_library
else :
sys.exit("ppocr_rec C static library not found !!! Please use format: --rec_library")
if args.level == '1' or args.level == '2' :
level = int(args.level)
else :
level = 0
ppocr_det = KSNN('VIM4')
ppocr_rec = KSNN('VIM4')
print(' |---+ KSNN Version: {} +---| '.format(ppocr_det.get_nn_version()))
print('Start init neural network ...')
ppocr_det.nn_init(library=det_library, model=det_model, level=level)
ppocr_rec.nn_init(library=rec_library, model=rec_model, level=level)
print('Done.')
# usb camera
# cap = cv.VideoCapture(int(cap_num))
# mipi
pipeline = "v4l2src device=/dev/media0 io-mode=dmabuf ! queue ! video/x-raw,format=YUY2,framerate=30/1 ! queue ! videoconvert ! appsink"
cap = cv.VideoCapture(pipeline, cv.CAP_GSTREAMER)
cap.set(3,1920)
cap.set(4,1080)
frame_counter = 0;
camera_id = "XzWz75mg6ZKB3S28QedR"
while(1):
frame_counter += 1
ret,orig_img = cap.read()
start = time.time()
det_img = cv.resize(orig_img, (det_input_size[1], det_input_size[0])).astype(np.float32)
det_img[:, :, 0] = (det_img[:, :, 0] - det_mean[0]) / det_var[0]
det_img[:, :, 1] = (det_img[:, :, 1] - det_mean[1]) / det_var[1]
det_img[:, :, 2] = (det_img[:, :, 2] - det_mean[2]) / det_var[2]
det_output = ppocr_det.nn_inference(det_img, input_shape=(det_input_size[0], det_input_size[1], 3), input_type="RAW", output_shape=[(det_input_size[0], det_input_size[1], 1)], output_type="FLOAT")
det_results = ocr_det_postprocess(det_output[0], orig_img, det_input_size)
final_results = []
for i in range(len(det_results)):
xmin, ymin, xmax, ymax, _, _ = det_results[i]
rec_img = orig_img[ymin:ymax, xmin:xmax]
new_height = rec_input_size[0]
new_width = int(new_height / rec_img.shape[0] * rec_img.shape[1])
if new_width > rec_input_size[1] * 1.2:
# text too long. If you want to detect it, please convert rec model input longer.
continue
elif new_width < rec_input_size[1] * 1.2 and new_width > rec_input_size[1]:
new_width = rec_input_size[1]
rec_img = cv.resize(rec_img, (new_width, new_height)).astype(np.float32)
padding_img = np.zeros((rec_input_size[0], rec_input_size[1], 3)).astype(np.float32)
padding_img[:, :new_width] = rec_img
padding_img = (padding_img - rec_mean) / rec_var
rec_output = ppocr_rec.nn_inference(padding_img, input_shape=(rec_input_size[0], rec_input_size[1], 3), input_type="RAW", output_shape=[(rec_output_size[0], rec_output_size[1])], output_type="FLOAT")
det_results[i][5] = ocr_rec_postprocess(rec_output[0])
print('results')
print(det_results[i])
probability = det_results[i][4]
text = det_results[i][5]
print(f'probability: {probability}')
print(f'text: {text}')
print(f'text length: {len(text)}')
final_results.append(det_results[i])
# if len(text) == 1 and probability > 0.5 and text in texts_data:
# final_results.append(det_results[i])
if det_results is not None:
pil_img, cv_img = draw(orig_img, final_results)
cv_img = cv.resize(cv_img, (1280, 720))
end = time.time()
print('Done. inference time: ', end - start)
cv.imshow("capture", cv_img)
if cv.waitKey(1) & 0xFF == ord('q'):
break
ppocr_det.nn_destory_network()
ppocr_rec.nn_destory_network()
cap.release()
cv.destroyAllWindows()
For the color_detection and color_utils are same as above.
postprocess.py
import cv2
import numpy as np
from shapely.geometry import Polygon
import pyclipper
det_box_thresh = 0.2
min_size = 5
unclip_ratio = 1.5
character_str = ["blank"]
with open("./data/symbol.txt", "rb") as fin:
#with open("./data/en_dict.txt", "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode("utf-8").strip("\n").strip("\r\n")
character_str.append(line)
character_str.append(" ")
ignored_token = [0]
def ocr_det_postprocess(det_output, original_image, det_input_size):
outs = cv2.findContours((det_output * 255).astype(np.uint8), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
if len(outs) == 3:
contours = outs[1]
elif len(outs) == 2:
contours = outs[0]
det_results = []
for i in range(len(contours)):
bounding_box = cv2.boundingRect(contours[i])
if bounding_box[2] < min_size or bounding_box[3] < min_size:
continue
mask = np.ones((bounding_box[3], bounding_box[2]), dtype=np.uint8)
tmp_det_output = det_output.reshape(det_input_size[0], det_input_size[1])
score = cv2.mean(tmp_det_output[bounding_box[1]:bounding_box[1] + bounding_box[3], bounding_box[0]:bounding_box[0] + bounding_box[2]], mask)[0]
if score < det_box_thresh:
continue
box = np.array(((bounding_box[0], bounding_box[1]),
(bounding_box[0] + bounding_box[2], bounding_box[1]),
(bounding_box[0] + bounding_box[2], bounding_box[1] + bounding_box[3]),
(bounding_box[0], bounding_box[1] + bounding_box[3])))
poly = Polygon(box)
distance = poly.area * unclip_ratio / poly.length
offset = pyclipper.PyclipperOffset()
offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
expanded = offset.Execute(distance)
tmp_box = np.array(expanded)
xmin = max(int(np.min(tmp_box[0, :, 0]) / det_input_size[1] * original_image.shape[1]), 0)
ymin = max(int(np.min(tmp_box[0, :, 1]) / det_input_size[0] * original_image.shape[0]), 0)
xmax = min(int(np.max(tmp_box[0, :, 0]) / det_input_size[1] * original_image.shape[1] + 1), original_image.shape[1])
ymax = min(int(np.max(tmp_box[0, :, 1]) / det_input_size[0] * original_image.shape[0] + 1), original_image.shape[0])
det_results.append([xmin, ymin, xmax, ymax, score, 0])
return det_results
def ocr_rec_postprocess(rec_output):
rec_idx = rec_output.argmax(axis=1)
rec_prob = rec_output.max(axis=1)
selection = np.ones(len(rec_idx), dtype=bool)
selection[1:] = rec_idx[1:] != rec_idx[:-1]
selection &= rec_idx != ignored_token
#print(f'rec_idx: {rec_idx}')
#print(f'selection: {selection}')
#print(f'rec_output: {rec_output}')
#print(f'character_str: {character_str}')
char_list = [character_str[text_id] for text_id in rec_idx[selection]]
character_result = "".join(char_list)
return character_result
symbol.txt
+
-
×
÷