The new version is much better. I found something with the tensorflow.
The inference is 8x times faster than darknet, however the post processing after the “nn_inference” in mobilenet-ssd takes forever and end up much slower than darknet.
Any thoughts?
It would be great to have something that runs at 60-70 FPS realtime.
@Vignesh_Raja About the post process with SSD, I use a lot of for loop. This operation is extremely slow in python. You should use numpy functions instead of for loop.
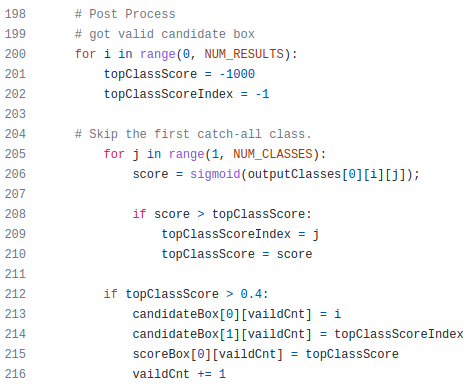
@Frank Yes. Here is the problem. I tried replacing with Numpy arrays. But I could not understand the why “NUM RESULTS” is 1917 and the idea behind this code. Any help here would be appreciated!
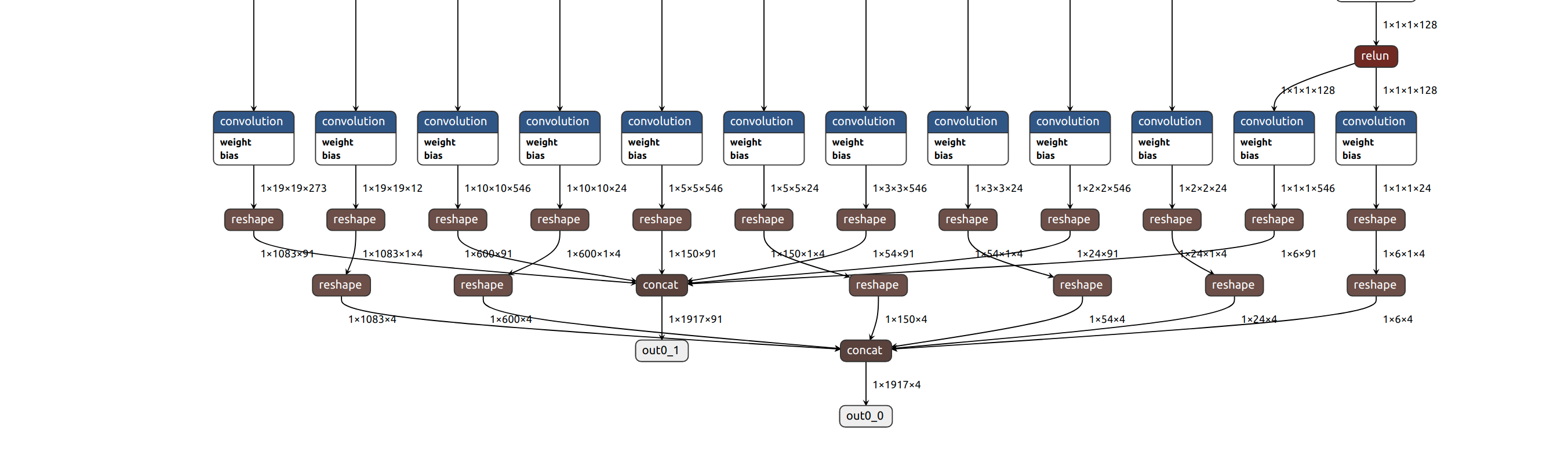
Each convolution goes through two convolutions to get different data.
Output layer 0 is used to save coordinate point information,It will be reshape to 1*x*4
Output layer 1 is used to save category information. It will be reshape to 1*x*91(91 is num class)
You can do sigmoid before for loop. numpy can do the same operation on the entire array at once. Then I think numpy.where() function will help you to filter out the subscripts of the score data you need. These data are the last data you need