Hello @pigpigfang ,
原模型精度偏低,使用int8量化精度量化精度低的模型损失会更大一点。这边试了一下int16量化,效果和原模型几乎差不多了。
另外,如果实际使用场景图片输入大小和你提供的测试图片大小相同,建议使用padding。这个宽高比直接resize形变比较大。
原模型结果
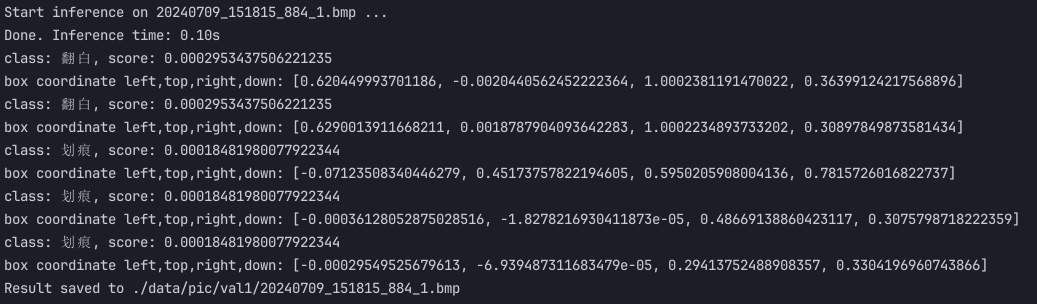
int16量化模型结果
转换命令
./convert --model-name yolov8n_customer \
--platform onnx \
--model yolov8n_customer.onnx \
--mean-values '0 0 0 0.00392156' \
--quantized-dtype dynamic_fixed_point \
--qtype int16 --source-files ./dataset.txt \
--kboard VIM3 --print-level 0 \
--iterations 500
修改部分代码
def draw(image, boxes, scores, classes, padding_image):
for box, score, cl in zip(boxes, scores, classes):
x1, y1, x2, y2 = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(x1, y1, x2, y2))
x1 *= padding_image.shape[1]
y1 *= padding_image.shape[0]
x2 *= padding_image.shape[1]
y2 *= padding_image.shape[0]
left = max(0, np.floor(x1 + 0.5).astype(int))
top = max(0, np.floor(y1 + 0.5).astype(int))
right = min(image.shape[1], np.floor(x2 + 0.5).astype(int))
bottom = min(image.shape[0], np.floor(y2 + 0.5).astype(int))
cv.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2)
cv.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(left - 50, top + 20),
cv.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
def init_ksnn():
yolov8 = KSNN('VIM3')
print(' |---+ KSNN Version: {} +---| '.format(yolov8.get_nn_version()))
print('Start init neural network ...')
yolov8.nn_init(library='./models/libnn_yolov8n_customer_int16.so', model='./models/yolov8n_customer_int16.nb', level=1)
print('Done.')
return yolov8
def get_input_data(input_folder,yolov8,output_folder):
try:
for filename in os.listdir(input_folder):
if filename.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp')): # 仅处理图片文件
input_path = os.path.join(input_folder, filename)
output_path = os.path.join(output_folder, filename)
# 读取并预处理图片
orig_img = cv.imread(input_path, cv.IMREAD_COLOR)
orig_img_height, orig_img_width, _ = orig_img.shape
if orig_img_height > orig_img_width:
new_width = orig_img_height
new_height = orig_img_height
else:
new_width = orig_img_width
new_height = orig_img_width
padding_img = np.zeros((new_height, new_width, 3))
padding_img[:orig_img_height, :orig_img_width] = orig_img
img = cv.resize(padding_img, (640, 640)).astype(np.float32)
cv_img = list()
img[:, :, 0] = img[:, :, 0] - mean[0]
img[:, :, 1] = img[:, :, 1] - mean[1]
img[:, :, 2] = img[:, :, 2] - mean[2]
img = img / var[0]
img = img.transpose(2, 0, 1)
cv_img.append(img)
# 模型推理
print(f'Start inference on {filename} ...')
start = time.time()
data = yolov8.nn_inference(cv_img, platform='ONNX',reorder='2 1 0', output_tensor=3,output_format=output_format.OUT_FORMAT_FLOAT32)
end = time.time()
print(f'Done. Inference time: {end - start:.2f}s')
input0_data = data[2]
input1_data = data[1]
input2_data = data[0]
input0_data = input0_data.reshape(SPAN, LISTSIZE, GRID0, GRID0)
input1_data = input1_data.reshape(SPAN, LISTSIZE, GRID1, GRID1)
input2_data = input2_data.reshape(SPAN, LISTSIZE, GRID2, GRID2)
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
boxes, scores, classes = yolov8_post_process(input_data)
if boxes is not None:
draw(orig_img, boxes, scores, classes, padding_img)
# 保存结果
cv.imwrite(output_path, orig_img)
print(f'Result saved to {output_path}')
except Exception as e:
print(f'Error occurred: {e}')