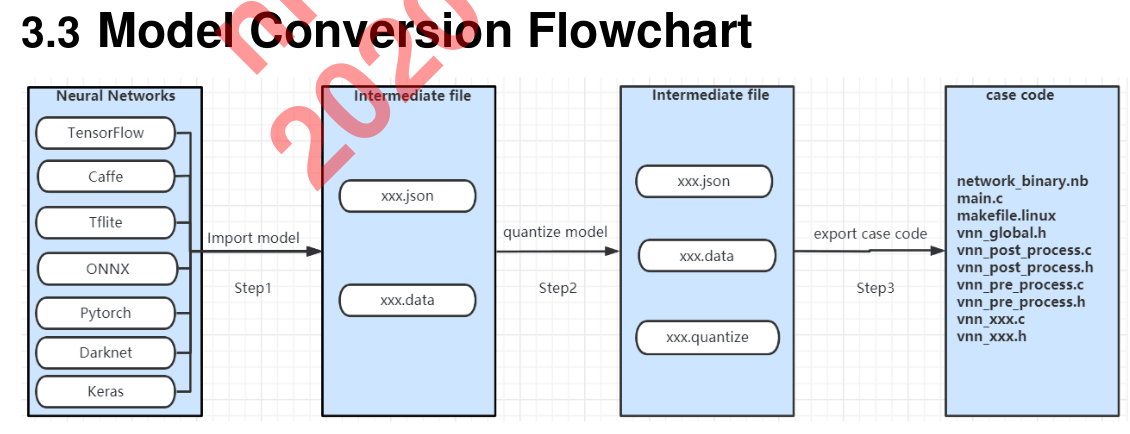
I read about converting models from tensorflow, caffe and etc., to proper code and then compiling it to generate binary executables on Khadas VIM3.
Now, my question is that is it possible that run my converted model inside a c++ code? I want to have a C++ code and inside my code run the model.
My other question is that is it possible that load the model to NPU and run it for different outputs? As I want it to run fast and low overhead it is important to run it efficiently. As my model is constant and I want to run it for different inputs, Is it possible that load my converted model(inside my C++ code) and run it with different inputs in several time slots.
Our sample demo source code use C++ to compile, you can follow it to build you own C++ project.
If you need to use different outputs and different inputs, you can extract the output and input layers of the neural network model and self-implement in C++ code
My application runs the model approximately every 150ms. My goal is to initially load the model at NPU and at each call just feed input and run it, instead of loading the model each time. Is it possible to load the model and at every run just feed the input to it? I have done it on another NPU with this method:
Hi @Frank
I try to compile the case code with calng++, but it fails. compiling case code with clang is successful. Is there a way to generate c++ compatible case code or is there a flag for clang++ that could compile it?
I need to use the case code(I think case code is a code that is required to load and run the model) inside a c++ code so using clang for compiling my project is not possible. (This is the reason that I want to find a way to compile case code with clang++).
I see the mentioned repository. However, when I use the android toolkit of Khadas NPU, it first converts the desired neural network model and then generates its case code which is in C language(vnn_pre_process.c, vnn_post_process.c, vnn_inceptionv3.c, main.c). When I cross-compile this case code with clang it is OK, but when I compile it with clang++ it fails. Is it possible to handle our desired model with c++ instead of c. for example generate c++ case code instead of C, or another way to use npu for a desired neural network?