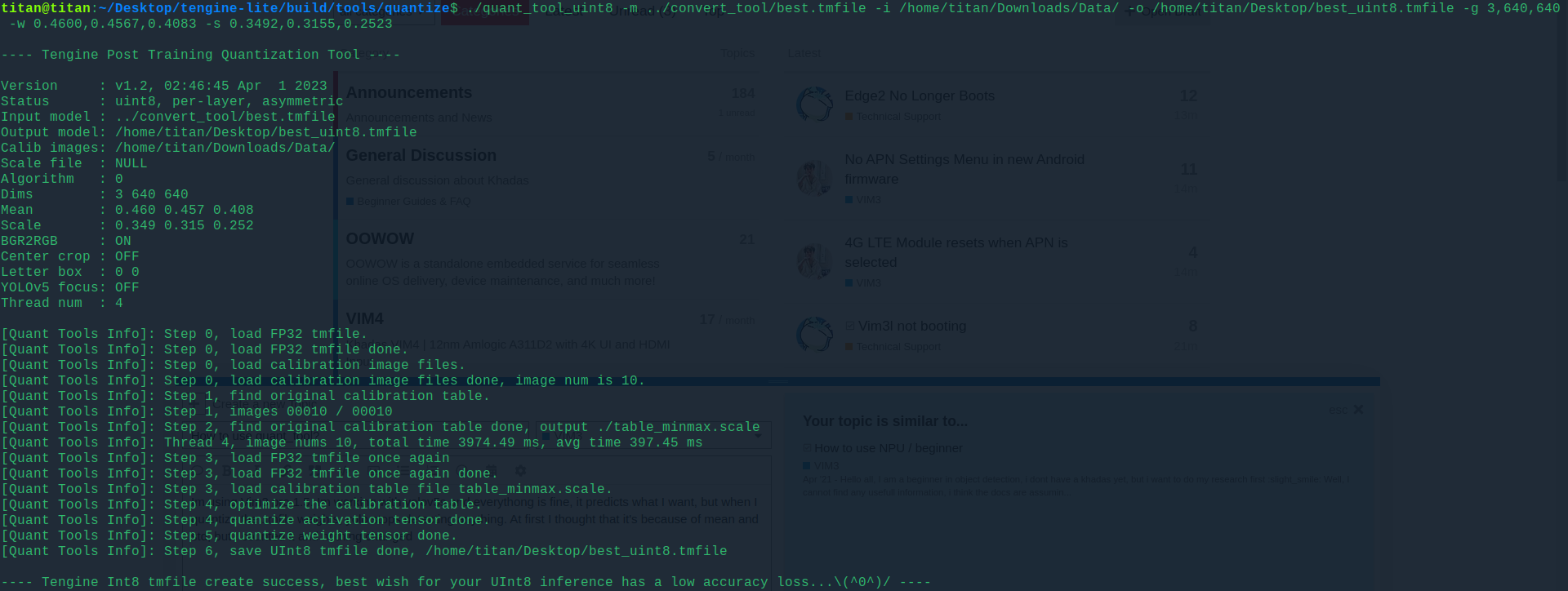
Im using Vim3 pro 1.5. Im working with yolov5s and everythong is fine, it predicts what I want, but when I quantize the .tmfile weights, yolo stops detecting anything. At first I thought that it’s because of mean and std, but I counted it and nothing changed
@Agent_kapo its not issue of conversion tool. The same performance drop can be seen with using quantized weights with any NN model. This issue is presented because of converting floating point values to fixed point values. FP32 will offer the highest precision and have higher computational requirements.
You can read about how we can get away with using INT8 fixed point for computation in most cases.
but when the quantized weights are just not accurate enough for the model. it will just give garbage inference.
In this case, prefer to run model without quantization.
because for me it’s strange, model works with yolo dataset where 88 clasess and a lot of data, and in my dataset is 19 clasess and 5.000 photos. So why is it like this?
Do not quantize for best results. Whatever unsupported operations that cannot run on the NPU will run on the CPU and it won’t comprimise on performance/accuracy balance.
Is best.tmfile quantized ? can you explain the models you are using to compare here.
If I wont quantize then whats the point to buy khadas with npu?
Here is my github:
I changed yolo.py (added method forward_export, which Im using when Im exporting pt to onnx)
Then Im exporting it in tmfile and quantizing it
Before everything worked well. Your Yolo with 88 classes, my customn dataset with chess, but this time no