Which system do you use? Android, Ubuntu, OOWOW or others?
Others
Which version of system do you use? Please provide the version of the system here:
Target: Yocto.
Host: Ubuntu 24.04
Please describe your issue below:
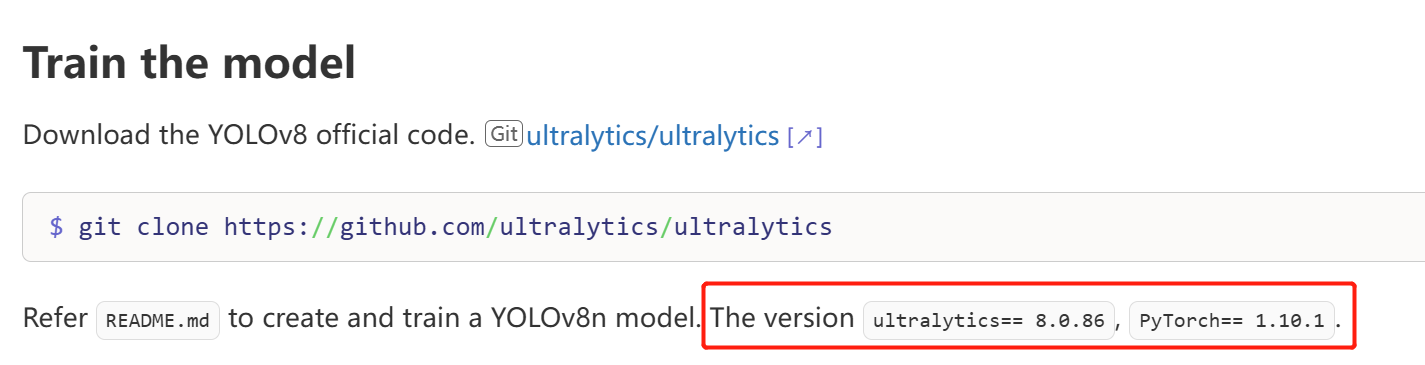
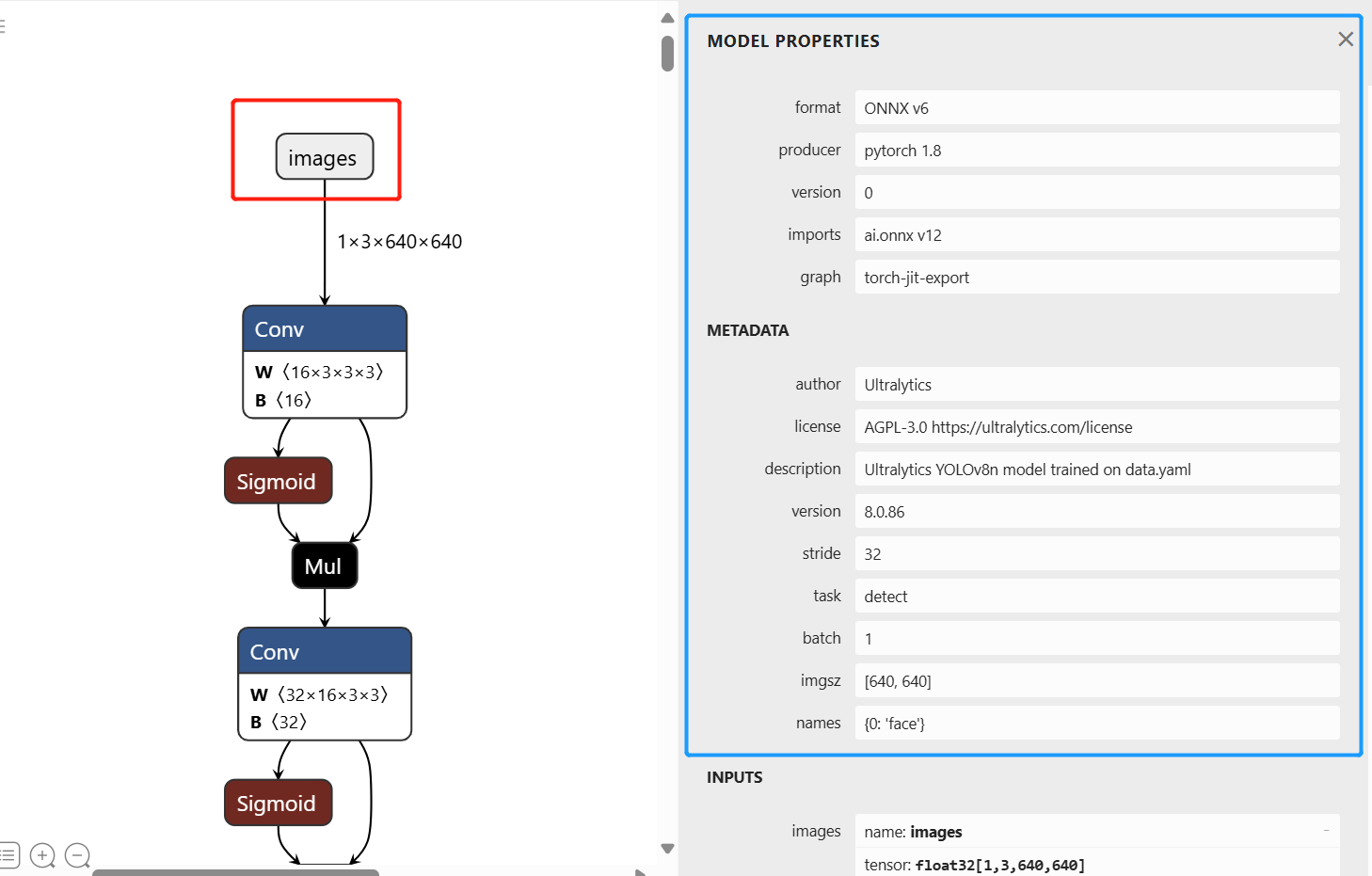
I took a pre-trained model (yolov8n.pt) and converted to onnx using the script + patch (export.py) given in vim3_demo_lite website. I installed docker too.
Then when I run the bash convert-in-docker.sh I get error from acuitylib/onnx_ir/onnx_numpy_backend/smart_toolkit.py file, where I search for code, then I couldn’t find it in the cloned sdk repo. But I assume it to be running inside the docker. The detailed log is listed below.
On an initial look, it looks like a compatibility issue between the version of ultralytics that runs/installed on the host vs the docker. But I didn’t look into the code in detail, and thought if can ask here to see if there are any quick fixes / solution.
Post a console log of your issue below:
(myenv) emb-aanahcn@cariqserver:~/labs/yolo/aml_npu_sdk$ bash convert-in-docker.sh
docker run -it --name npu-vim3 --rm -v /home/emb-aanahcn/labs/yolo/aml_npu_sdk:/home/khadas/npu -v /etc/localtime:/etc/localtime:ro -v /etc/timezone:/etc/timezone:ro -v /home/emb-aanahcn:/home/emb-aanahcn numbqq/npu-vim3
2024-10-14 14:42:47.525038: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/khadas/npu/acuity-toolkit/bin/acuitylib
2024-10-14 14:42:47.525071: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
I Namespace(import='onnx', input_dtype_list=None, input_size_list=None, inputs=None, model='./model/yolov8n.onnx', output_data='yolov8n.data', output_model='yolov8n.json', outputs=None, size_with_batch=None, which='import')
I Start importing onnx...
WARNING: ONNX Optimizer has been moved to https://github.com/onnx/optimizer.
All further enhancements and fixes to optimizers will be done in this new repo.
The optimizer code in onnx/onnx repo will be removed in 1.9 release.
W Call onnx.optimizer.optimize fail, skip optimize
I Current ONNX Model use ir_version 10 opset_version 19
I Call acuity onnx optimize 'eliminate_option_const' success
/home/khadas/npu/acuity-toolkit/bin/acuitylib/acuitylib/onnx_ir/onnx_numpy_backend/ops/split.py:15: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
if inputs[1] == '':
W Call acuity onnx optimize 'froze_const_branch' fail, skip this optimize
I Call acuity onnx optimize 'froze_if' success
I Call acuity onnx optimize 'merge_sequence_construct_concat_from_sequence' success
I Call acuity onnx optimize 'merge_lrn_lowlevel_implement' success
Traceback (most recent call last):
File "pegasus.py", line 131, in <module>
File "pegasus.py", line 112, in main
File "acuitylib/app/importer/commands.py", line 245, in execute
File "acuitylib/vsi_nn.py", line 171, in load_onnx
File "acuitylib/app/importer/import_onnx.py", line 123, in run
File "acuitylib/converter/onnx/convert_onnx.py", line 61, in __init__
File "acuitylib/converter/onnx/convert_onnx.py", line 761, in _shape_inference
File "acuitylib/onnx_ir/onnx_numpy_backend/shape_inference.py", line 65, in infer_shape
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_graph_engine.py", line 70, in smart_onnx_scanner
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_node.py", line 48, in calc_and_assign_smart_info
File "acuitylib/onnx_ir/onnx_numpy_backend/smart_toolkit.py", line 636, in multi_direction_broadcast_shape
ValueError: operands could not be broadcast together with shapes (1,0,160,160) (1,16,160,160)
[9] Failed to execute script pegasus
2024-10-14 14:42:50.712274: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/khadas/npu/acuity-toolkit/bin/acuitylib
2024-10-14 14:42:50.712351: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
I Namespace(channel_mean_value='0 0 0 0.0039215', generate='inputmeta', input_meta_output='yolov8n_inputmeta.yml', model='yolov8n.json', separated_database=False, source_file='dataset.txt', which='generate')
I Load model in yolov8n.json
Traceback (most recent call last):
File "pegasus.py", line 131, in <module>
File "pegasus.py", line 123, in main
File "acuitylib/app/console/commands.py", line 58, in execute
File "acuitylib/acuitynet.py", line 147, in load_file
File "acuitylib/acuitynet.py", line 510, in load
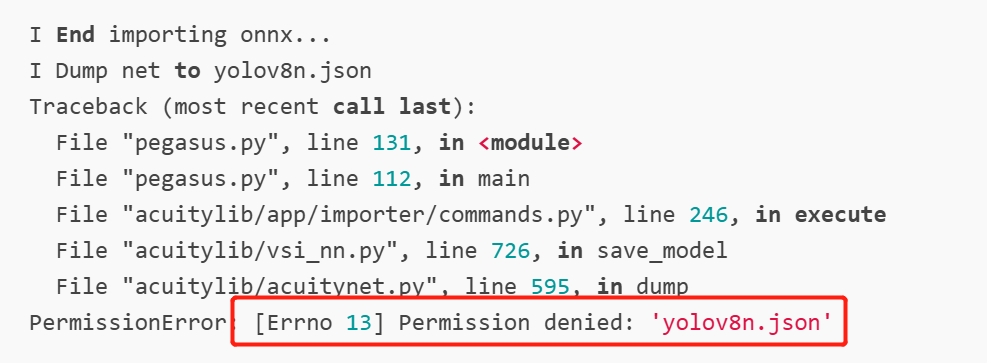
FileNotFoundError: [Errno 2] No such file or directory: 'yolov8n.json'
[76] Failed to execute script pegasus
0_import_model.sh: line 81: warning: here-document at line 24 delimited by end-of-file (wanted `COMMENT')
2024-10-14 14:42:52.793470: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/khadas/npu/acuity-toolkit/bin/acuitylib
2024-10-14 14:42:52.793510: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
I Namespace(MLE=False, algorithm='normal', batch_size=0, compute_entropy=False, device=None, divergence_first_quantize_bits=11, divergence_nbins=0, hybrid=False, iterations=1, model='yolov8n.json', model_data='yolov8n.data', model_quantize=None, moving_average_weight=0.01, output_dir=None, qtype='int8', quantizer='dynamic_fixed_point', rebuild=True, rebuild_all=False, which='quantize', with_input_meta='yolov8n_inputmeta.yml')
2024-10-14 14:42:54.173359: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-10-14 14:42:54.180799: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 2245780000 Hz
2024-10-14 14:42:54.182223: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5f0dbe0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2024-10-14 14:42:54.182253: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2024-10-14 14:42:54.183577: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/khadas/npu/acuity-toolkit/bin/acuitylib
2024-10-14 14:42:54.183596: W tensorflow/stream_executor/cuda/cuda_driver.cc:312] failed call to cuInit: UNKNOWN ERROR (303)
2024-10-14 14:42:54.183618: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (0c80a6be6d85): /proc/driver/nvidia/version does not exist
I Load model in yolov8n.json
Traceback (most recent call last):
File "pegasus.py", line 131, in <module>
File "pegasus.py", line 108, in main
File "acuitylib/app/medusa/commands.py", line 204, in execute
File "acuitylib/vsi_nn.py", line 280, in load_model
File "acuitylib/acuitynet.py", line 510, in load
FileNotFoundError: [Errno 2] No such file or directory: 'yolov8n.json'
[113] Failed to execute script pegasus