量化用的指令:
$tensorzone
–dtype float32
–action quantization
–source text
–source-file dataset.txt
–channel-mean-value ‘0 0 0 256’
–model-input ${NAME}.json
–model-data ${NAME}.data
–quantized-dtype dynamic_fixed_point-i16
–quantized-rebuild
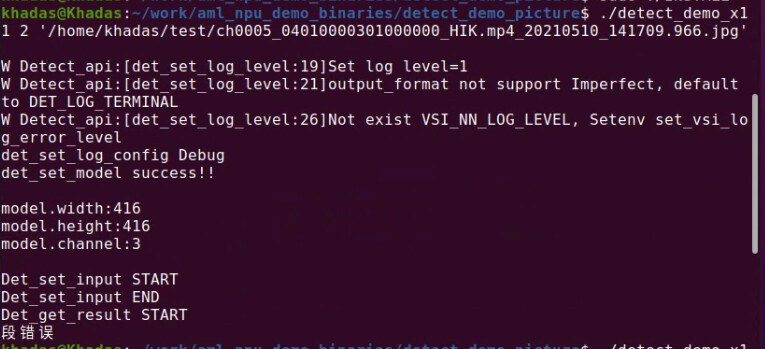
int8没有问题但是精度不高,u8可以编译后运行标签全部在一行且不正确,int16运行直接报段错误。另外正常运行的int8,如果输入的图片是416X416的也会报段错误
你好
- int16情况:
量化时:
tensorzone
–dtype float32
–action quantization
–source text
–source-file dataset.txt
–channel-mean-value ‘0 0 0 256’
–model-input ${NAME}.json
–model-data ${NAME}.data
–quantized-dtype dynamic_fixed_point-i16
–quantized-rebuild
导出case:
export_ovxlib
–model-input ${NAME}.json
–data-input ${NAME}.data
–reorder-channel ‘2 1 0’
–channel-mean-value ‘0 0 0 256’
–export-dtype float
–model-quantize ${NAME}.quantize
–optimize VIPNANOQI_PID0X88
–viv-sdk …/bin/vcmdtools
–pack-nbg-unify
按文档编译后替换模型和so,运行demo
Frank
7
@yarude Int16转换出来的代码,不能直接替换到我们代码里面,这个demo处理不了int16,你要自己设计demo
Frank
8
这也是同样的问题,不能直接使用demo,处理方式是不同的
Frank
9
@yarude 我们板子也有tengine的示例,你可以对比使用,但是两者的demo对图片的前后处理方式上是有差别的,所有精度上也会有差别,通常来说,tengine的精度会相对高一些
yarude
12
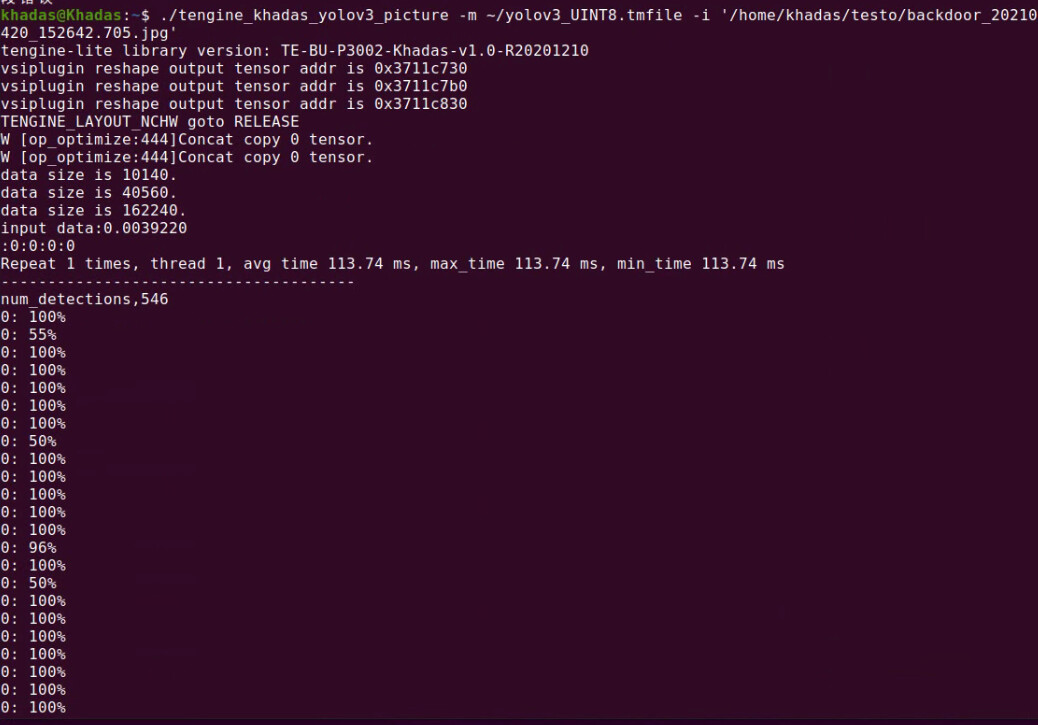
Tengine编译的我放在本机运行不了,放在盒子上可以运行,但是一直显示%值,也不结束
Frank
13
@yarude Tengine的在本机肯定是运行不了的,这本来就是为板子写的demo,里面是个while循环,你可以Ctrl+C结束.你看源码就知道了
yarude
14
@Frank 好的,已经通了,就是加载模型比aml的慢,另外精度虽然好一些了,但是和原始差距还是满大的,请问还有其他方式来提升精度么
Frank
15
@yarude 首先你要知道,跟原始demo是没办法比精度的,你的模型从float降到int,精度上就不在一个量级上。你要求NPU上达到原始模型精度就是不现实的。
如果是你现在这种需求,你只有手动去修改模型,适配NPU,手动去实现近似转换。
这个,两者的加载方式上是不一样的。tengine属于在线转换,aml属于提前转换好的。tengine只是在加载时慢,识别速度上,两者没有多大区别