@librazxc 这边确认了,已经是放出了,你可以下载最新的SDK试试
@Frank 您好,阅读aml_npu_sdk_6.4.3/docs里的DDK_6.4.3_SDK_V1.6 API 描述.pdf,想请问里头提及到的libnnsdk.so是指在哪个SDK呀?我已经下载了6.4.3的npu_sdk和gitlab的源码,没有搜索到这个文件?我是不是还缺少一个SDK

@Frank 您好,我发现你们gitlab上aml_app_demo path/to/detect_library/model_code/detect_yolo_v3_tiny 这个还是旧版本的。
1 Like
@Frank 您好,我参考最新的HowToConvertToUseNPU,有一个疑惑咨询一下:
我将自己的cfg和weights经过docs转换成功了,在VIM3板子上进行了推理,是有结果的,但我感觉比我之前使用其他板子的模型转换工具精度降低了很多,量化也是采用的是google那一套的量化方式。我就是开始检查预处理的问题,之前也咨询过咱们这边了解到,aml_npu_app demo yolo里的预处理都是转为[-1,1],也看到了yolov3_process.c确实是这么处理的

那么我自己的实际情况是[0,1],因此就按照此链接HowToConvertToUseNPU里
--channel-mean-value '0 0 0 256' --reorder-channel '2 1 0'这么操作了,疑惑是该docs链接里并没有说明预处理[0,1]时,对应的
yolov3_process.c里yolov3_preprocess函数是否也该需要修改?
可能我哪里理解不够到位,不知道我理解的对不对?或者说对输入图直接scale到[0,1]的操作在其他地方做了。
@librazxc 这你可以看转换完成的vnn_yolo_xx.c和vnn_yolo_xx.h,scale在[0,1]以及[-1,1]时,值是不一样的.这里是对输入的值做上下限设置的.如果你是256的,这里需要修改数字值就可以
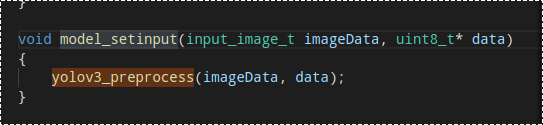
@librazxc Docs里面没有对这一块做详细的描写,这毕竟只是个demo,实际应用起来,还是需要另外写代码的.你如果需要保证精度的话,这里是需要修改的,按照你设置的上下限来修改就行.
/*-----------------------------------------
Register client ops
-----------------------------------------*/
/*-----------------------------------------
Node definitions
-----------------------------------------*/
/*-----------------------------------------
lid - nbg_0
var - node[0]
name - nbg
operation - nbg
input - [416, 416, 3, 1]
output - [13, 13, 255, 1]
[26, 26, 255, 1]
[52, 52, 255, 1]
-----------------------------------------*/
NEW_VXNODE(node[0], VSI_NN_OP_NBG, 1, 3, 0);
node[0]->nn_param.nbg.type = VSI_NN_NBG_FILE;
node[0]->nn_param.nbg.url = data_file_name;
/*-----------------------------------------
Tensor initialize
-----------------------------------------*/
attr.dtype.fmt = VSI_NN_DIM_FMT_NCHW;
/* @input_0:out0 */
attr.size[0] = 416;
attr.size[1] = 416;
attr.size[2] = 3;
attr.size[3] = 1;
attr.dim_num = 4;
attr.dtype.fl = 7;
attr.dtype.qnt_type = VSI_NN_QNT_TYPE_DFP;
NEW_NORM_TENSOR(norm_tensor[0], attr, VSI_NN_TYPE_INT8);
/* @output_82:out0 */
attr.size[0] = 13;
attr.size[1] = 13;
attr.size[2] = 255;
attr.size[3] = 1;
attr.dim_num = 4;
attr.dtype.fl = 2;
attr.dtype.qnt_type = VSI_NN_QNT_TYPE_DFP;
NEW_NORM_TENSOR(norm_tensor[1], attr, VSI_NN_TYPE_INT8);
/* @output_94:out0 */
attr.size[0] = 26;
attr.size[1] = 26;
attr.size[2] = 255;
attr.size[3] = 1;
attr.dim_num = 4;
attr.dtype.fl = 2;
attr.dtype.qnt_type = VSI_NN_QNT_TYPE_DFP;
NEW_NORM_TENSOR(norm_tensor[2], attr, VSI_NN_TYPE_INT8);
/* @output_106:out0 */
attr.size[0] = 52;
attr.size[1] = 52;
attr.size[2] = 255;
attr.size[3] = 1;
attr.dim_num = 4;
attr.dtype.fl = 2;
attr.dtype.qnt_type = VSI_NN_QNT_TYPE_DFP;
NEW_NORM_TENSOR(norm_tensor[3], attr, VSI_NN_TYPE_INT8);
这里,你可以尝试调整1_quantize_model.sh里面的参数,你会看到结果是不一样的.
使用asymmetric_affine-u8.你会发现导出的文件是使用scale,而不是fl
这套工具新的SDK里面的文档对如何调试更准确的参数有很多描述,你可以多看看.

@librazxc 你可以使用 vsi_nn_DtypeToFloat32 这个函数试试.这部分代码得等我有空看看,很多没弄这个了,你可以把数据打印出来,你在到处vnn_postpress.c里面可以看到关于这个fl的用法,如果你需要用vsi_nn_DtypeToFloat32.建议你参考导出的vnn_postpress.c,我们的代码也是参考这个的
你好,我在自己的模型使用export_case_code.sh转换生成的vnn_post_process.c里,新版sdk6.4.3.7 使用dynamic_fixed_point-i8量化方式得到的vnn_post_process.c如下,没有找到关于dtype.fl的用法
Summary(vnn_post_process.c)
/****************************************************************************
* Generated by ACUITY 5.11.0
* Match ovxlib 1.1.21
*
* Neural Network appliction post-process source file
****************************************************************************/
/*-------------------------------------------
Includes
-------------------------------------------*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "vsi_nn_pub.h"
#include "vnn_global.h"
#include "vnn_post_process.h"
#define _BASETSD_H
/*-------------------------------------------
Variable definitions
-------------------------------------------*/
/*{graph_output_idx, postprocess}*/
const static vsi_nn_postprocess_map_element_t* postprocess_map = NULL;
/*-------------------------------------------
Functions
-------------------------------------------*/
static void save_output_data(vsi_nn_graph_t *graph)
{
uint32_t i;
#define _DUMP_FILE_LENGTH 1028
#define _DUMP_SHAPE_LENGTH 128
char filename[_DUMP_FILE_LENGTH] = {0}, shape[_DUMP_SHAPE_LENGTH] = {0};
vsi_nn_tensor_t *tensor;
for(i = 0; i < graph->output.num; i++)
{
tensor = vsi_nn_GetTensor(graph, graph->output.tensors[i]);
vsi_nn_ShapeToString( tensor->attr.size, tensor->attr.dim_num,
shape, _DUMP_SHAPE_LENGTH, FALSE );
snprintf(filename, _DUMP_FILE_LENGTH, "output%u_%s.dat", i, shape);
vsi_nn_SaveTensorToBinary(graph, tensor, filename);
}
}
static vsi_bool get_top
(
float *pfProb,
float *pfMaxProb,
uint32_t *pMaxClass,
uint32_t outputCount,
uint32_t topNum
)
{
uint32_t i, j, k;
#define MAX_TOP_NUM 20
if (topNum > MAX_TOP_NUM) return FALSE;
memset(pfMaxProb, 0xfe, sizeof(float) * topNum);
memset(pMaxClass, 0xff, sizeof(float) * topNum);
for (j = 0; j < topNum; j++)
{
for (i=0; i<outputCount; i++)
{
for (k=0; k < topNum; k ++)
{
if(i == pMaxClass[k])
break;
}
if (k != topNum)
continue;
if (pfProb[i] > *(pfMaxProb+j))
{
*(pfMaxProb+j) = pfProb[i];
*(pMaxClass+j) = i;
}
}
}
return TRUE;
}
static vsi_status show_top5
(
vsi_nn_graph_t *graph,
vsi_nn_tensor_t *tensor
)
{
vsi_status status = VSI_FAILURE;
uint32_t i,sz,stride;
float *buffer = NULL;
uint8_t *tensor_data = NULL;
uint32_t MaxClass[5];
float fMaxProb[5];
uint32_t topk = 5;
sz = 1;
for(i = 0; i < tensor->attr.dim_num; i++)
{
sz *= tensor->attr.size[i];
}
if(topk > sz)
topk = sz;
stride = vsi_nn_TypeGetBytes(tensor->attr.dtype.vx_type);
tensor_data = (uint8_t *)vsi_nn_ConvertTensorToData(graph, tensor);
buffer = (float *)malloc(sizeof(float) * sz);
for(i = 0; i < sz; i++)
{
status = vsi_nn_DtypeToFloat32(&tensor_data[stride * i], &buffer[i], &tensor->attr.dtype);
}
if (!get_top(buffer, fMaxProb, MaxClass, sz, topk))
{
printf("Fail to show result.\n");
goto final;
}
printf(" --- Top%d ---\n", topk);
for(i = 0; i< topk; i++)
{
printf("%3d: %8.6f\n", MaxClass[i], fMaxProb[i]);
}
status = VSI_SUCCESS;
final:
if(tensor_data)vsi_nn_Free(tensor_data);
if(buffer)free(buffer);
return status;
}
vsi_status vnn_PostProcessYolotiny(vsi_nn_graph_t *graph)
{
vsi_status status = VSI_FAILURE;
/* Show the top5 result */
status = show_top5(graph, vsi_nn_GetTensor(graph, graph->output.tensors[0]));
TEST_CHECK_STATUS(status, final);
/* Save all output tensor data to txt file */
save_output_data(graph);
final:
return VSI_SUCCESS;
}
const vsi_nn_postprocess_map_element_t * vnn_GetPostPorcessMap()
{
return postprocess_map;
}
uint32_t vnn_GetPostPorcessMapCount()
{
if (postprocess_map == NULL)
return 0;
else
return sizeof(postprocess_map) / sizeof(vsi_nn_postprocess_map_element_t);
}
这里我差不多理解是定点法,整体部分还原小数部分
3.还有咱们转后的模型是NCHW的还是NHWC的呀?
4.以及量化的时候我使用batch-size=200张图量化会导致显存不够,如何解决?是否有batch=1,epochs=200的设置方式
@librazxc 你转换前是NCHW,转换后就是NCHW.转换前后是一致的.
这个问题最好的方法就是加大你的显存,或者用CPU去转换.修改参数不是好的选择.我在转换时都是在CPU上面转,只有训练时,我是在GPU上的
@Frank 好的,谢谢。
如果我想在c308x上编译gitlab的yolo模型,除了修改build_vx.sh里的BUILD_OPTION_GPU_CONFIG="vipnanoqi_pid0x88"为pid0xa1,还需要怎么修改呢。
khadas 可能没有这个芯片,你可以向你的上游要这个转换的包,C308X 的包的一些文件是和 A311D 不同的,最好不要只修改这个文件。
此外,C308 默认应该是 6.4.3 了。
我目前工作的公司是 Open AI Lab,主要工作于 NPU 的后端,这是我同事的贴:
Tengine 支持 AML、RK NPU 第1篇
Tengine 支持 AML、RK NPU 第2篇
是时候搞懂NPU了
我们已经支持 VIP8K VIP9K,支持的芯片有 A311D,C308X,RV1109,RV1126 等。
上周五我们已经为 VIM3/VIM3L 准备的技术预览版,测试同学正在测试,一两天内就可以给到 KHADAS 团队,到时候可以在 VIM3/VIM3L 上体验一下。
1 Like