1、问题描述
在对我的onnx模型进行转换的时候,由于是多输入,所以执行了文档说的./bin/pegasus import onnx这一步,在模型比较小的时候这一步是成功的,当我的模型较大的时候,发现转换模型的进程被kill了,原因是系统内存不够,我把系统内存从16G加到32G后还是一跑转换模型程序内存就很快100%然后系统自动kill进程,我觉得我就算加到64G内存也会很快满掉。
我想知道是程序不支持这么大的模型的转换还是转换程序发生内存泄漏了?
2、操作过程
- sdk为6.4.4.3版本
- 操作系统为Ubuntu 20.04.2 LTS
- 其他环境是照着requirements.txt装的
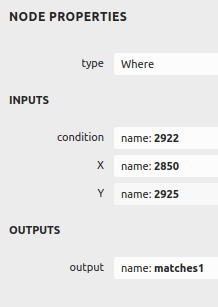
- 网络模型为onnx格式,是通过pytorch的torch.onnx.export自动转换出来的,模型比较大,模型加权重一共有48.3MB,版本和输入输出如下:
其中对inputs的编号达到了两千多:
- 输入指令为:
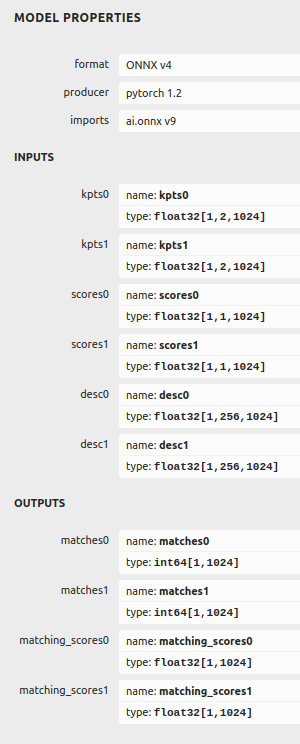
./bin/pegasus import onnx --model ./my_superglue.onnx --inputs "kpts0 kpts1 scores0 scores1 desc0 desc1" --input-size-list "2,1024#2,1024#1,1024#1,1024#256,1024#256,1024" --outputs "matches0 matches1 matching_scores0 matching_scores1" --output-model ./my_superglue.json --output-data ./my_superglue.data
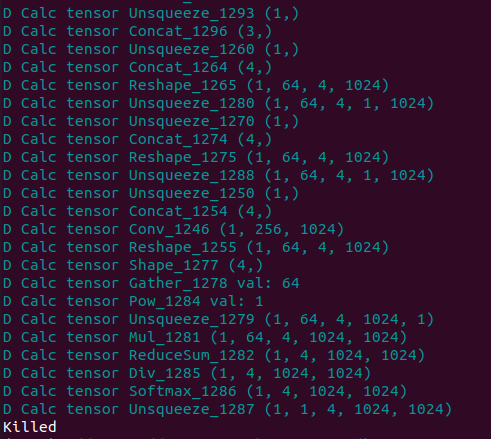
- 显示如下:
中间是很长的D Calc tensor …,无其他
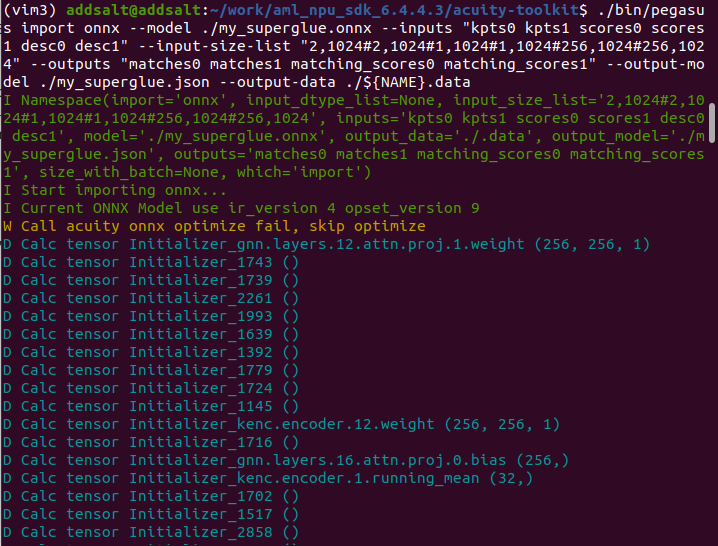
- 在电脑/var/log/kern.log里记录了内存不够kill进程
- 如果需要复现,我能提供我的onnx模型文件到邮箱
 SDK最多能支持多大的模型转换呢?
SDK最多能支持多大的模型转换呢?