Hello @livelove1987 ,
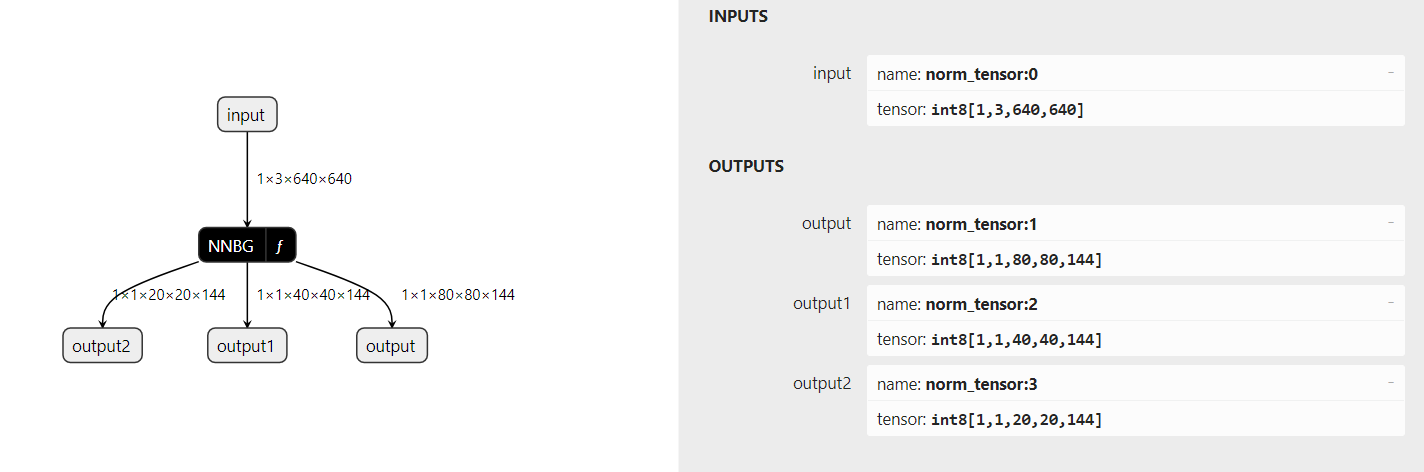
Why your model only has one output?
Have you change something for convert codes?
Our YOLOv8n rknn model.
Hello @livelove1987 ,
Why your model only has one output?
Have you change something for convert codes?
Our YOLOv8n rknn model.
Because im actualy using my own model. Here is the model in onnx format: license_plate_detector.onnx - file on EasyPaste.org
And than i also used script which you showed here for converting the yolov8.pt which i applied for my model and by that i got this result
license_plate_detector.weird_shape.onnx - file on EasyPaste.org
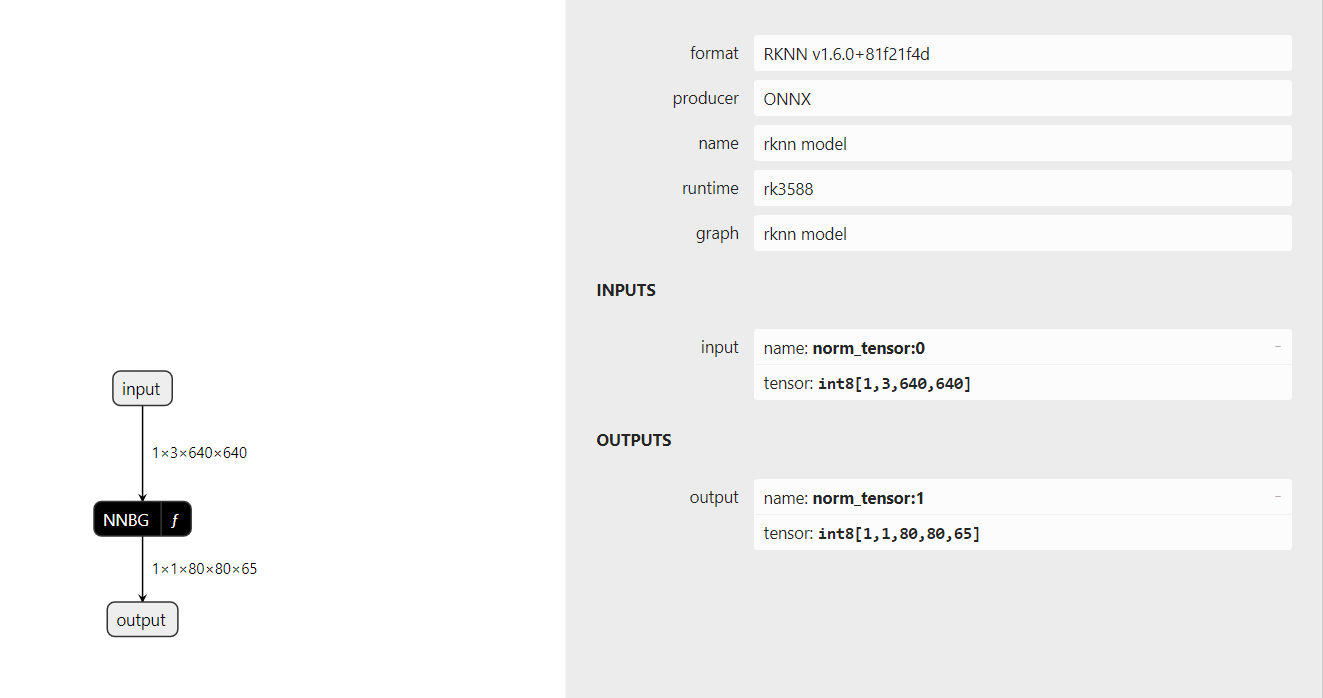
Okay sorry i did small mistake when converting my model now i fixed it and my rknn model looks fine:
But still dont know how to inference that ![]()
Hello @livelove1987 ,
First step create RKNN object.
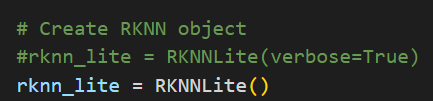
Second, load RKNN model.
Then, init environment.
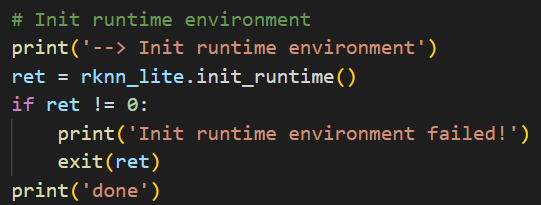
At last, inference.
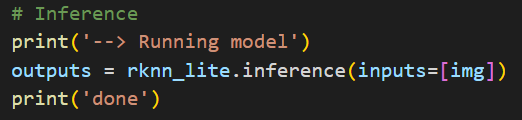
The whole codes.
Both of above codes are here.
edge2-npu/Python/ssd/ssd.py at master · khadas/edge2-npu (github.com)
Another thing, Edge2 must use RKNN convert tool v1.4 or v1.3. Your version, v1.6, is too high.
Okay so i need to downgrade it, im also realy curios what does the shape (1,1,80,80,65) mean, and if i want to extract values like bboxes of confidence how to locate it
Hello @livelove1987 ,
80×80 is the size of feature map. The last 65 is the information of each point on feature map.
Index 0-63 is the information of boxes. And the remains are confidence information. You model class only one. If model class is 80, the last one is 64+80=144.
Index 0-63 have 64 number. Average 4 group, 0-15, 16-31, 32-47, 48-63. Each of then mutiple a normal martix, this.
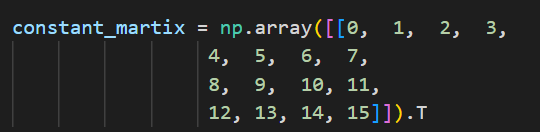
After multiple, you will get 4 number, x1, y1, x2, y2.
Then do the following calculation.
x1 = (x_local + 0.5 - x1) * feature_map_size
y1 = (y_local + 0.5 - y1) * feature_map_size
x2 = (x_local + 0.5 + x2) * feature_map_size
y2 = (y_local + 0.5 + y2) * feature_map_size
x_local and y_local are the coordinate of the point.
For example, on 80×80 feature map point (5, 7).
x1 = (5 + 0.5 - x1) * 80
y1 = (7 + 0.5 - y1) * 80
x2 = (5 + 0.5 + x2) * 80
y2 = (7 + 0.5 + y2) * 80
After this step, you will get results of boxes information. Please remember this results are the model input image but not are real image. So you need to convert the coordinate if you have resize image.
For the confidence, they need to do sigmoid.
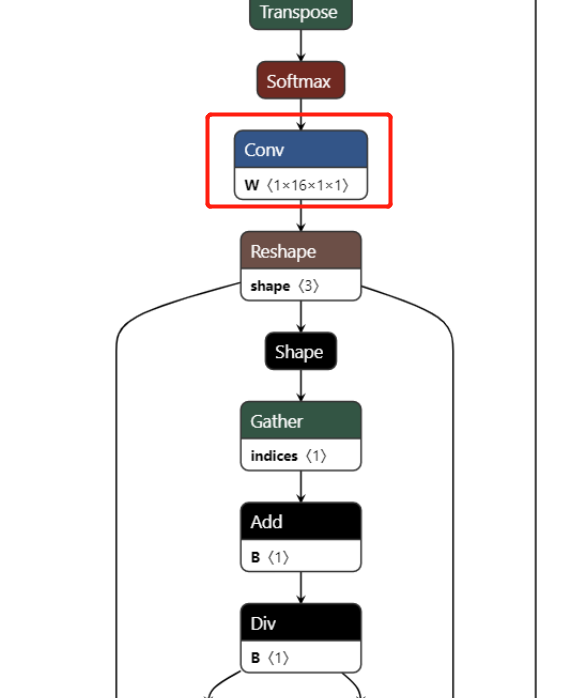
Above of all are the operation of this structure. It has been remove when you convert pt model to ONNX model.
Why you need to do it? Because RKNN tool this structure will quantize some important information to 0. Remove this structure and do the same operation in Python is one of the method.
Im really glad for your help about how to extract infromations from such output shape i found some github repo solving such yolov8 related problem
I dont understand what does this constant_matrix represent. Also why do you add 0.5 values to them? And how to assign confidence which represents that bbox to it?
Hello @livelove1987 ,
constant_matrix only is the weight of this convolutional layer.
As i know, it has no special meaning.
Add 0.5 means the center point of each feature map point. YOLOv8 official sets the result is based on center point.
Each feature map point has the box information and confidence information. 0-63 are about box, and the other are confidence of this box. If model has 80 classes, confidence information also are 80. Each information means the confidence of this class. For example, a model has 2 classes and confidence are [0.9, 0.1]. So, the class 0 confidence is 0.9. Class 1 confidence is 0.1.
Hi @Louis-Cheng-Liu ,
We’ve been following this thread to get our YOLOv8 models running on the RKNN3588 platform. We are having some issues when trying to convert from .onnx to .rknn, and here is the error:
We would like to know if we are doing it correctly, and i send you my github repository with my files GitHub - SebasRG99/YoloV8-To-RKNN.
We are using Ultralytics version 8.2.48 and Python 3.8.19. We made the modification you mentioned earlier in the file “ultralytics/nn/modules/head.py”, but we are not sure if we did it correctly. We attach the link to our repository where the head.py file is located so you can check if we made the modifications correctly.
After converting to .onnx, we tried to convert to .rknn using the file “onnx2rknn.py”, which is the script we are using for the conversion. I also changed my version of rknn-toolkit2 to v1.4.0, but when performing the conversion, it generates the error mentioned earlier. I am not sure what is causing it.
We appreciate any help you can provide. Thank you!
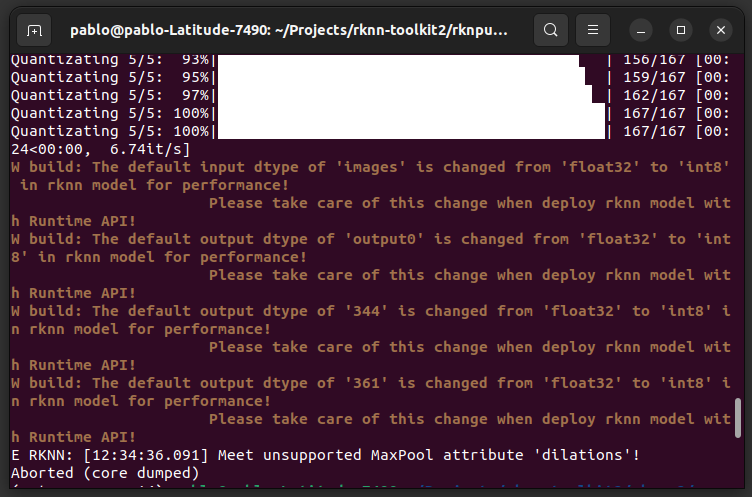
Hello @SebasRG99 ,
Your model modifications is right. I think it is the version of Pytorch or Ultralytics. The error means it does not support a Maxpool layer. Maybe Pytorch or Ultralytics update and RKNN does not support its changes.
Suggest you to use our version.
torch==1.10.1
ultralytics==8.0.86
Hello, thank you very much for your help! I changed my versions of Torch and Ultralytics to the ones you mentioned, and the model conversion was successful. Now, these days I have been trying to perform an inference using the converted model, but without much success, as I get the following error when attempting it:
I have also modified the file “/inference/inference_npu_cp38.py” to try to perform the inference, but when I run it, I get the error I mentioned earlier. I would greatly appreciate any guidance on what I am doing wrong or what modifications I need to make.
Thank you very much for your help!
Hello @SebasRG99 ,
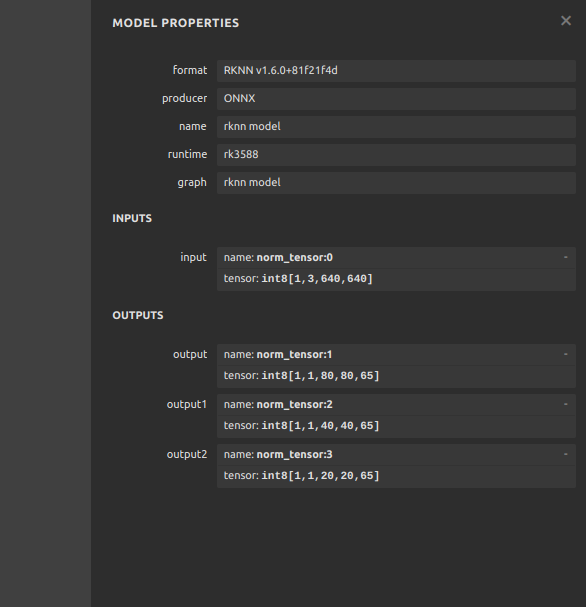
Your model’s outputs are as follows.
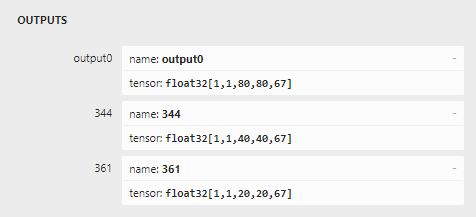
Your reshape matrix need to be same like it.
Edge2 has not YOLOv8 Python Demo. So, if you do not know how to do postprocess for YOLOv8 outputs, please refer this.
ksnn/examples/yolov8n/yolov8n-picture.py at master · khadas/ksnn (github.com)
Hi,
Thank you very much for the information. I am using the provided code as a basis to create one that suits my needs. I managed to modify it and perform the inference, but the results are not as expected. Here is the output image:
The code I am using for the inference is as follows:
import numpy as np
import os
import cv2 as cv
import time
from rknnlite.api import RKNNLite
GRID0 = 20
GRID1 = 40
GRID2 = 80
LISTSIZE = 67
NUM_CLS = 3
MAX_BOXES = 500
OBJ_THRESH = 0.4
NMS_THRESH = 0.5
mean = [0, 0, 0]
var = [255]
CLASSES = ("correcto", "ausente", "incorrecto")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x, axis=0):
x = np.exp(x)
return x / x.sum(axis=axis, keepdims=True)
def process_output(output, grid_size):
print(f'Original output shape: {output.shape}')
output = output.reshape(grid_size, grid_size, LISTSIZE)
print(f'Reshaped output: {output.shape}')
box_class_probs = sigmoid(output[..., :NUM_CLS])
box_0 = softmax(output[..., NUM_CLS: NUM_CLS + 16], -1)
box_1 = softmax(output[..., NUM_CLS + 16: NUM_CLS + 32], -1)
box_2 = softmax(output[..., NUM_CLS + 32: NUM_CLS + 48], -1)
box_3 = softmax(output[..., NUM_CLS + 48: NUM_CLS + 64], -1)
print(f'Box class probs shape: {box_class_probs.shape}')
print(f'Box 0 shape: {box_0.shape}')
print(f'Box 1 shape: {box_1.shape}')
print(f'Box 2 shape: {box_2.shape}')
print(f'Box 3 shape: {box_3.shape}')
result = np.zeros((grid_size, grid_size, 4))
for i in range(grid_size):
for j in range(grid_size):
result[i, j, 0] = np.dot(box_0[i, j], np.arange(16))
result[i, j, 1] = np.dot(box_1[i, j], np.arange(16))
result[i, j, 2] = np.dot(box_2[i, j], np.arange(16))
result[i, j, 3] = np.dot(box_3[i, j], np.arange(16))
col = np.tile(np.arange(0, grid_size), grid_size).reshape(-1, grid_size)
row = np.tile(np.arange(0, grid_size).reshape(-1, 1), grid_size)
col = col.reshape(grid_size, grid_size, 1)
row = row.reshape(grid_size, grid_size, 1)
grid = np.concatenate((col, row), axis=-1)
result[..., 0:2] = 0.5 - result[..., 0:2]
result[..., 0:2] += grid
result[..., 0:2] /= (grid_size, grid_size)
result[..., 2:4] = 0.5 + result[..., 2:4]
result[..., 2:4] += grid
result[..., 2:4] /= (grid_size, grid_size)
return result, box_class_probs
def filter_boxes(boxes, box_class_probs):
print(f'Filtering boxes with shape: {boxes.shape} and box_class_probs shape: {box_class_probs.shape}')
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_class_scores >= OBJ_THRESH)
boxes = boxes[pos[0], pos[1], :]
classes = box_classes[pos]
scores = box_class_scores[pos]
print(f'Filtered boxes: {boxes.shape}, classes: {classes.shape}, scores: {scores.shape}')
return boxes, classes, scores
def nms_boxes(boxes, scores):
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov8_post_process(outputs):
assert len(outputs) == 3, "Expected 3 outputs, got {}".format(len(outputs))
grid_sizes = [20, 40, 80]
boxes, classes, scores = [], [], []
for output, grid_size in zip(outputs, grid_sizes):
output = output.astype(np.float32) / 255.0 # Convertir int8 a float32 y normalizar
output = output.squeeze()
print(f'Processing output with shape {output.shape} for grid size {grid_size}')
b, c = process_output(output, grid_size)
b, c, s = filter_boxes(b, c)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes, axis=0)
classes = np.concatenate(classes, axis=0)
scores = np.concatenate(scores, axis=0)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes, axis=0)
classes = np.concatenate(nclasses, axis=0)
scores = np.concatenate(nscores, axis=0)
return boxes, scores, classes
def draw(image, boxes, scores, classes):
for box, score, cl in zip(boxes, scores, classes):
x1, y1, x2, y2 = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(x1, y1, x2, y2))
x1 *= image.shape[1]
y1 *= image.shape[0]
x2 *= image.shape[1]
y2 *= image.shape[0]
left = max(0, np.floor(x1 + 0.5).astype(int))
top = max(0, np.floor(y1 + 0.5).astype(int))
right = min(image.shape[1], np.floor(x2 + 0.5).astype(int))
bottom = min(image.shape[0], np.floor(y2 + 0.5).astype(int))
cv.rectangle(image, (left, top), (right, bottom), (255, 0, 0), 2)
cv.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(left, top - 6),
cv.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
if __name__ == '__main__':
rknn_model = '/home/orangepi/Desktop/Devices/Linux/Orange_Pi_RKNN3588/vision_server/start_inference/yoloV5/models/yolov8n-640-640_rk3588.rknn'
image_path = 'IMG_6425.rf.3eb8cb37b1601a9e198005f55b0a7084.jpg'
rknn = RKNNLite()
print('Loading RKNN model')
ret = rknn.load_rknn(rknn_model)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('Initializing RKNN runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init RKNN runtime environment failed')
exit(ret)
print('Reading image')
orig_img = cv.imread(image_path)
img = cv.resize(orig_img, (640, 640)).astype(np.float32)
img[:, :, 0] = img[:, :, 0] - mean[0]
img[:, :, 1] = img[:, :, 1] - mean[1]
img[:, :, 2] = img[:, :, 2] - mean[2]
img = img / var[0]
img = img.transpose(2, 0, 1)
img = np.expand_dims(img, axis=0) # Asegurarse de que la entrada tenga 4 dimensiones
print('Starting inference')
start = time.time()
outputs = rknn.inference(inputs=[img])
end = time.time()
print('Inference time: ', end - start)
print('Output shapes:', [output.shape for output in outputs])
input_data = [
outputs[2].reshape(1, 1, 20, 20, LISTSIZE),
outputs[1].reshape(1, 1, 40, 40, LISTSIZE),
outputs[0].reshape(1, 1, 80, 80, LISTSIZE)
]
boxes, scores, classes = yolov8_post_process(input_data)
if boxes is not None:
draw(orig_img, boxes, scores, classes)
cv.imwrite("./result.jpg", orig_img)
cv.imshow("results", orig_img)
cv.waitKey(0)
rknn.release()
I have made more modifications, but I haven’t been able to get the boxes to draw correctly. If you could give me any advice or assistance, I would greatly appreciate it.
Thank you in advance.
Hello @SebasRG99 ,
First problem is preprocess.
img = cv.resize(orig_img, (640, 640)).astype(np.float32)
img[:, :, 0] = img[:, :, 0] - mean[0]
img[:, :, 1] = img[:, :, 1] - mean[1]
img[:, :, 2] = img[:, :, 2] - mean[2]
img = img / var[0]
img = img.transpose(2, 0, 1)
img = np.expand_dims(img, axis=0)
Our Edge2 has not YOLOv8 Python Demo. The link we provide is our VIM3 KSNN YOLOv8 Python Demo. KSNN Demo need to do normalization first, so i only suggest you refer postprocess codes. Edge2 RKNN does not need to do it. About preprocess part, you can refer this code.
edge2-npu/Python/ssd/ssd.py at master · khadas/edge2-npu (github.com)
Another problem is this.
output = output.astype(np.float32) / 255.0
RKNN model’s outputs are float32. You should not do again.
Hello, @Louis-Cheng-Liu
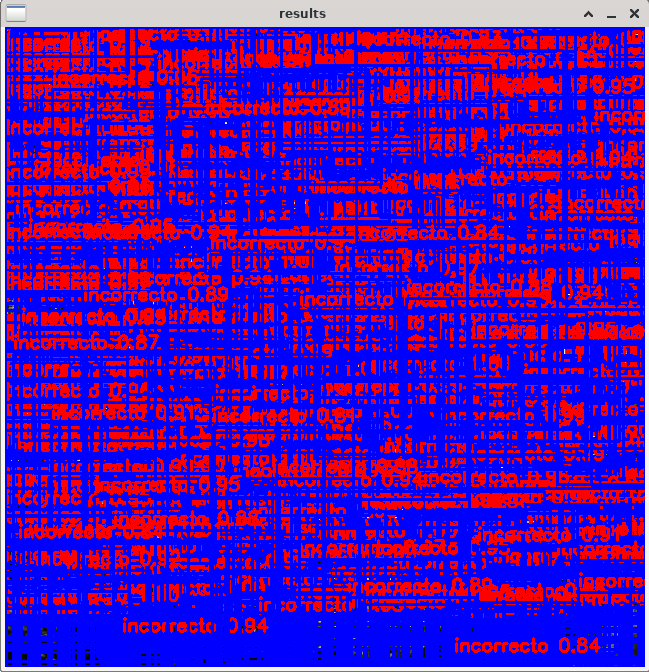
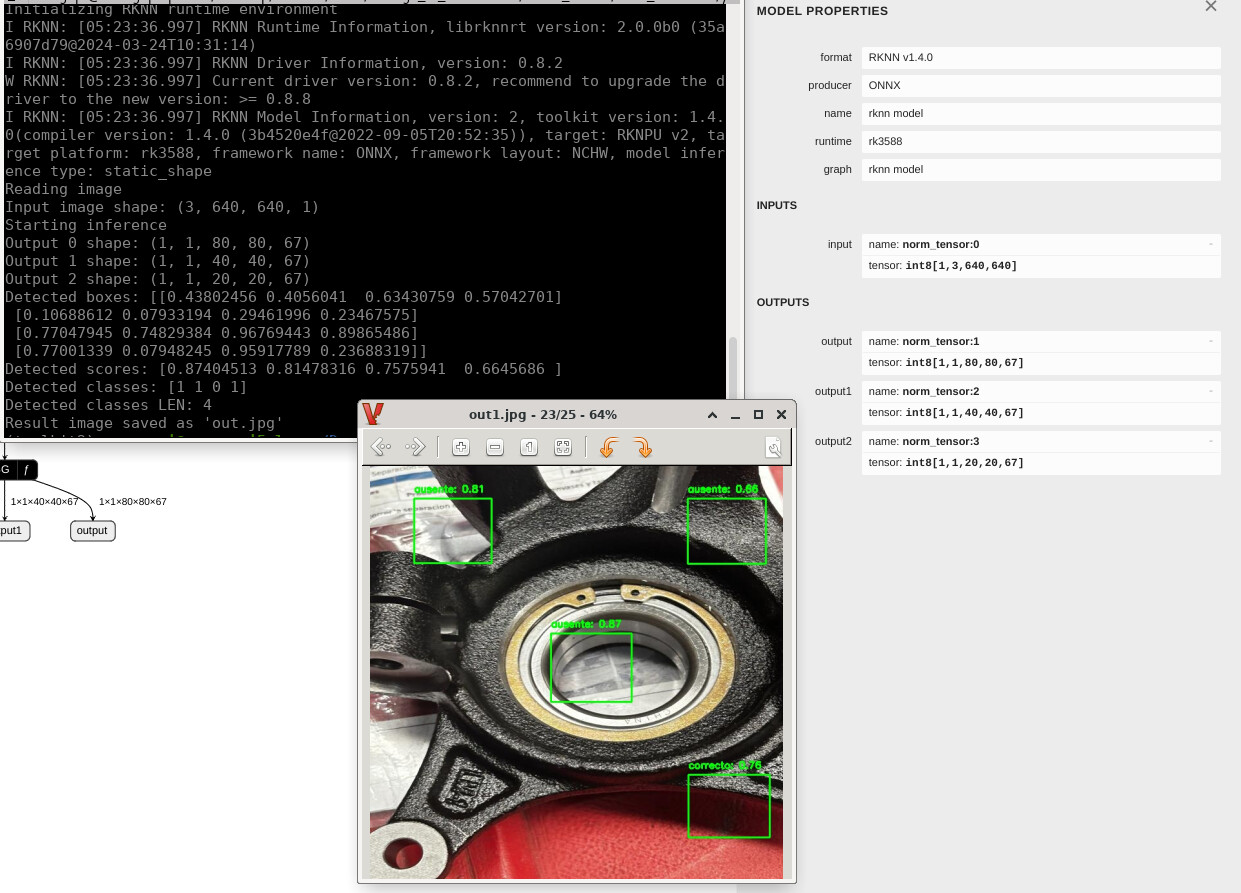
thank you very much for all the help you have provided so far. Thanks to your guidance, I have been working hard these past few days and I believe I have managed to improve the inference. I no longer have the error that showed many classes in the image, but now the detection boxes are not being drawn correctly, and it seems that the last class (incorrect) is never being detected
The previous image should only show one box.I have been making modifications, but I still can’t figure out if the error is occurring when drawing the boxes on the image or during the processing part. The code I have been working on is the following:
import numpy as np
import os
import cv2 as cv
import time
from rknnlite.api import RKNNLite
GRID0 = 20
GRID1 = 40
GRID2 = 80
LISTSIZE = 67
NUM_CLS = 3
OBJ_THRESH = 0.5
NMS_THRESH = 0.45
CLASSES = ("correcto", "ausente", "incorrecto")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def softmax(x, axis=0):
x = np.exp(x)
return x / x.sum(axis=axis, keepdims=True)
def process_output(output, grid_size):
output = output.reshape(grid_size, grid_size, LISTSIZE)
box_class_probs = sigmoid(output[..., :NUM_CLS])
box_0 = softmax(output[..., NUM_CLS: NUM_CLS + 16], -1)
box_1 = softmax(output[..., NUM_CLS + 16: NUM_CLS + 32], -1)
box_2 = softmax(output[..., NUM_CLS + 32: NUM_CLS + 48], -1)
box_3 = softmax(output[..., NUM_CLS + 48: NUM_CLS + 64], -1)
result = np.zeros((grid_size, grid_size, 4))
for i in range(grid_size):
for j in range(grid_size):
result[i, j, 0] = np.dot(box_0[i, j], np.arange(16))
result[i, j, 1] = np.dot(box_1[i, j], np.arange(16))
result[i, j, 2] = np.dot(box_2[i, j], np.arange(16))
result[i, j, 3] = np.dot(box_3[i, j], np.arange(16))
col = np.tile(np.arange(0, grid_size), grid_size).reshape(-1, grid_size)
row = np.tile(np.arange(0, grid_size).reshape(-1, 1), grid_size)
col = col.reshape(grid_size, grid_size, 1)
row = row.reshape(grid_size, grid_size, 1)
grid = np.concatenate((col, row), axis=-1)
result[..., 0:2] = 0.5 - result[..., 0:2]
result[..., 0:2] += grid
result[..., 0:2] /= grid_size
result[..., 2:4] = 0.5 + result[..., 2:4]
result[..., 2:4] += grid
result[..., 2:4] /= grid_size
return result, box_class_probs
def filter_boxes(boxes, box_class_probs):
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_class_probs, axis=-1)
pos = np.where(box_class_scores >= OBJ_THRESH)
boxes = boxes[pos[0], pos[1], :]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores, nms_thresh):
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= nms_thresh)[0]
order = order[inds + 1]
return keep
def yolov8_post_process(outputs):
grid_sizes = [20, 40, 80]
boxes, classes, scores = [], [], []
for output, grid_size in zip(outputs, grid_sizes):
output = output.squeeze()
b, c = process_output(output, grid_size)
b, c, s = filter_boxes(b, c)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes, axis=0)
classes = np.concatenate(classes, axis=0)
scores = np.concatenate(scores, axis=0)
keep = nms_boxes(boxes, scores, NMS_THRESH)
boxes = boxes[keep]
classes = classes[keep]
scores = scores[keep]
return boxes, scores, classes
if __name__ == '__main__':
rknn_model_path = '/home/orangepi/Desktop/Devices/Linux/Orange_Pi_RKNN3588/vision_server/start_inference/yoloV5/models/functionalModels/yolov8n-640-640_rk3588.rknn'
image_path = '14.jpg'
rknn = RKNNLite()
print('Loading RKNN model')
ret = rknn.load_rknn(rknn_model_path)
if ret != 0:
print('Load RKNN model failed')
exit(ret)
print('Initializing RKNN runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init RKNN runtime environment failed')
exit(ret)
print('Reading image')
orig_img = cv.imread(image_path)
img = cv.resize(orig_img, (640, 640)).astype(np.float32)
img = img.transpose(2, 0, 1)
img = np.expand_dims(img, axis=-1)
print('Input image shape:', img.shape)
print('Starting inference')
outputs = rknn.inference(inputs=[img])
for i, output in enumerate(outputs):
print(f'Output {i} shape:', output.shape)
input_data = [
outputs[2].reshape(1, 1, 20, 20, LISTSIZE),
outputs[1].reshape(1, 1, 40, 40, LISTSIZE),
outputs[0].reshape(1, 1, 80, 80, LISTSIZE)
]
boxes, scores, classes = yolov8_post_process(input_data)
if boxes is not None and len(scores) > 0:
print('Detected boxes:', boxes)
print('Detected scores:', scores)
print('Detected classes:', classes)
print('Detected classes LEN:', len(classes))
# Dibujar las detecciones en la imagen original
for i in range(len(boxes)):
box = boxes[i]
score = scores[i]
cl = classes[i]
x1, y1, x2, y2 = box
x1 = int(x1 * orig_img.shape[1])
y1 = int(y1 * orig_img.shape[0])
x2 = int(x2 * orig_img.shape[1])
y2 = int(y2 * orig_img.shape[0])
cv.rectangle(orig_img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv.putText(orig_img, f'{CLASSES[cl]}: {score:.2f}', (x1, y1 - 10), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv.imwrite("out1.jpg", orig_img)
print("Result image saved as 'out.jpg'")
else:
print('No objects detected')
rknn.release()
I would greatly appreciate any additional help and guidance you can offer to resolve this new problem.
Hello @SebasRG99 ,
Have you refered Edge2 ssd codes we provided?
You do not need to do transpose and expand_dims for input image.
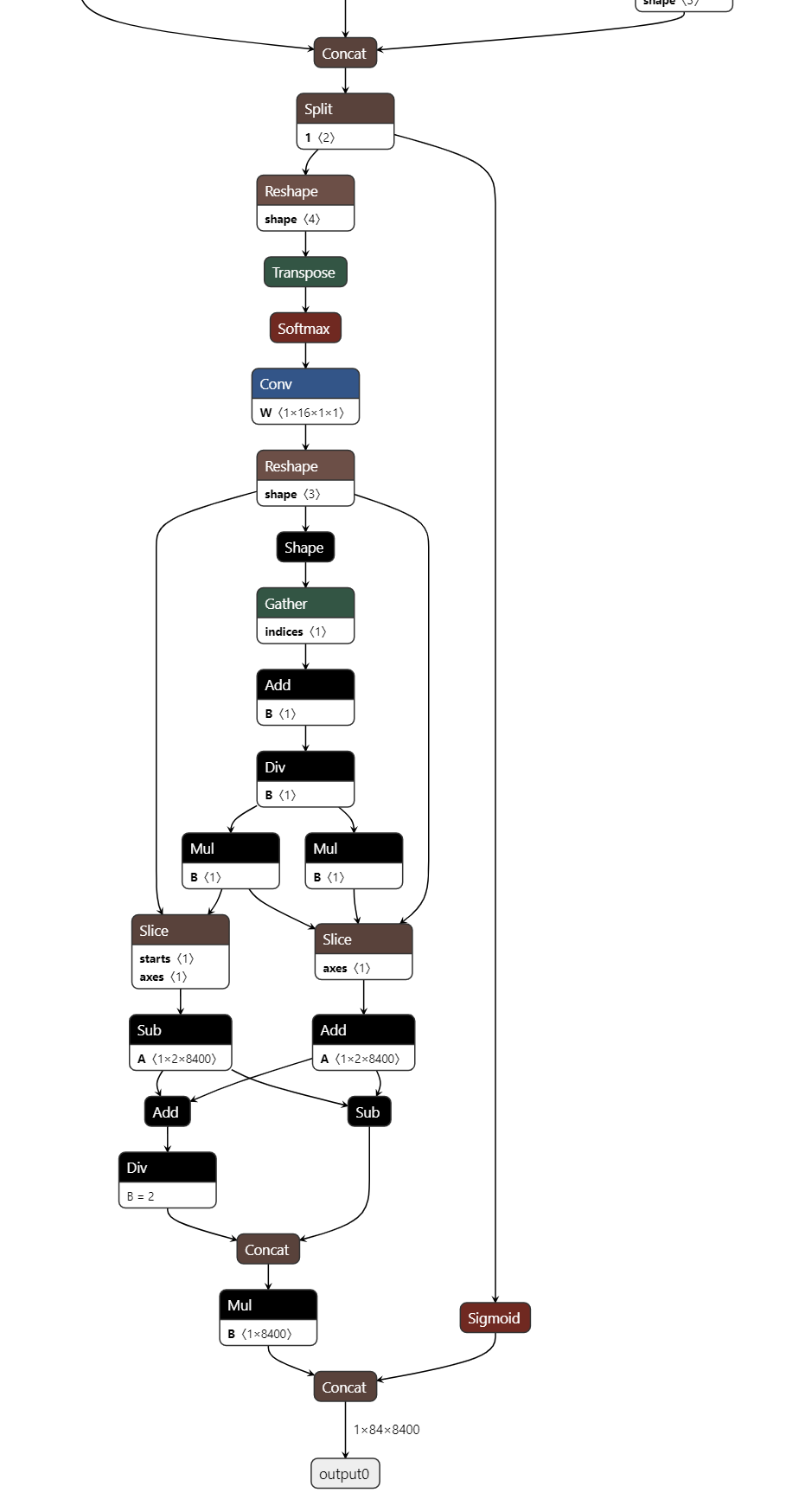
Hello everyone. I carefully studied the chat history and I managed to make a model with three outputs. But here: rknn_model_zoo/examples/yolo11 at main · airockchip/rknn_model_zoo · GitHub the presented model has as many as 9 outputs. How to achieve this result when converting the original YOLO11?